Machine Learning no Direito
Conceitos, Aplicações e Problemas
Julio Trecenti
Doutor em estatística pelo IME-USP

|
Diretor na Associação Brasileira de Jurimetria |

|
Sócio na Terranova Consultoria |

|
Pós-doc em Jurimetria no CEOE-Unifesp |

|
Sócio na Curso-R |
|
Professor TP no Insper |
O que é Machine Learning?
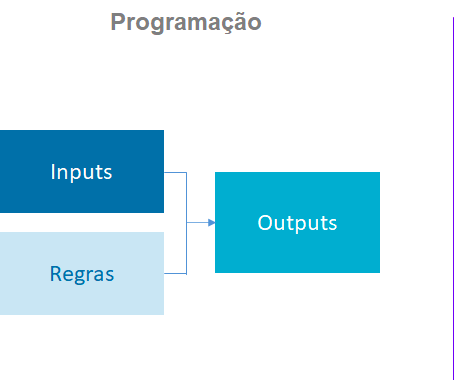
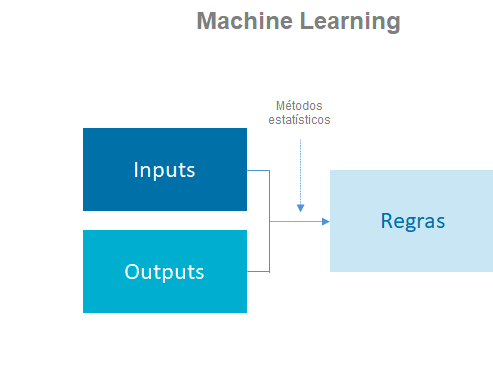
Modelagem preditiva
Área da estatística destinada à construção de modelos estatísticos capazes de fornecer boas predições para determinado fenômeno.
Bom livro:

- Outra boa referência: AME
E as redes neurais?
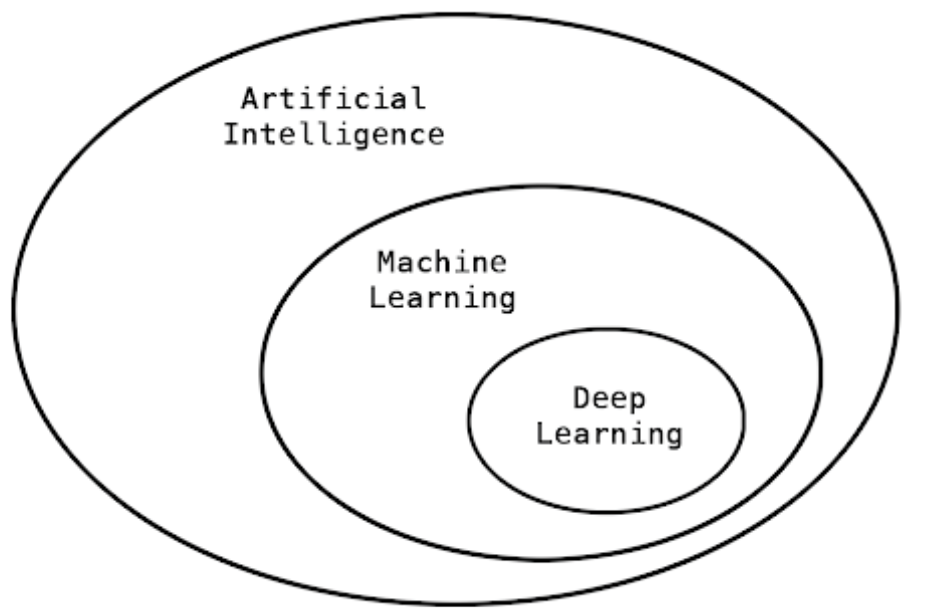
E a inteligência artificial?

A inteligência artificial está machine learning nos dias de hoje.
IA no Direito = Jurimetria?
IA no Direito \(\neq\) Jurimetria!
Jurimetria é a aplicação da estatística no direito. Ela é usada para descobrir regras jurídicas a partir das marcas que o Direito deixa na sociedade.
Exemplo jurídico: CARF
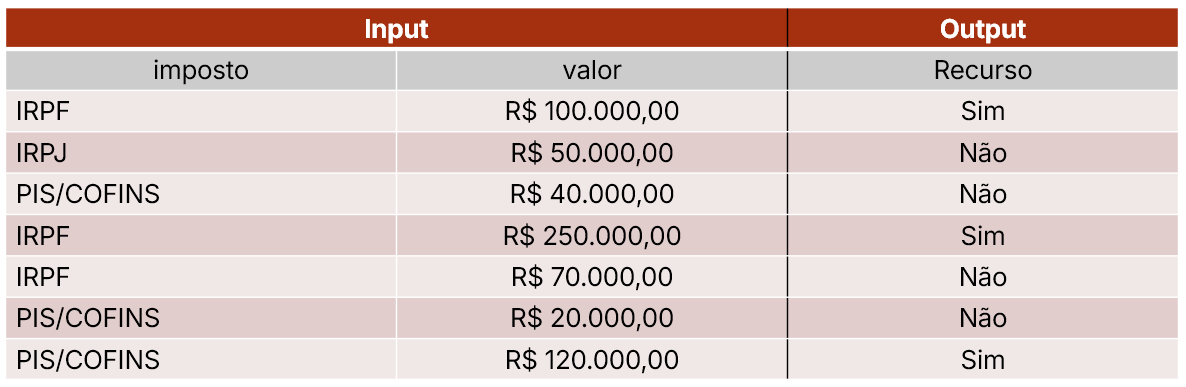
Regra: ?
Exemplo jurídico: CARF
Regra: se valor \(\geq\) 100 \(\rightarrow\) recurso
Aplicações de IA no Direito

Sobreajuste
Para isso, podemos aplicar um modelo super complexo, que se ajusta perfeitamente aos dados que observamos, como se cada caso fosse um caso…
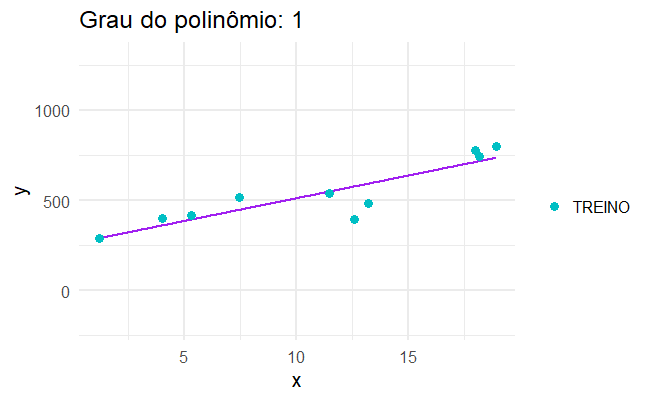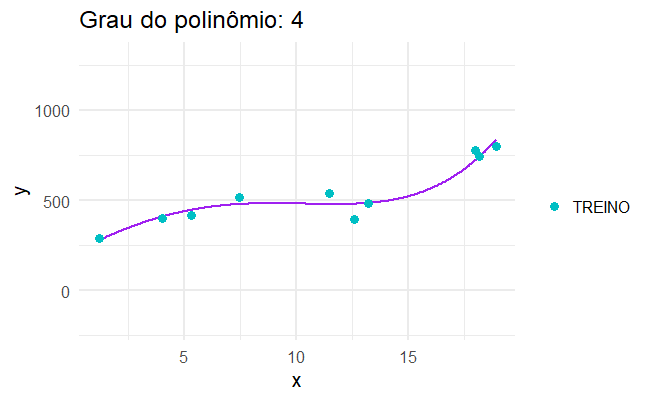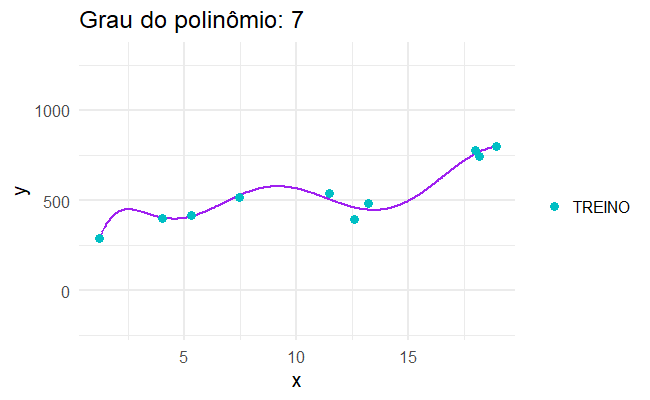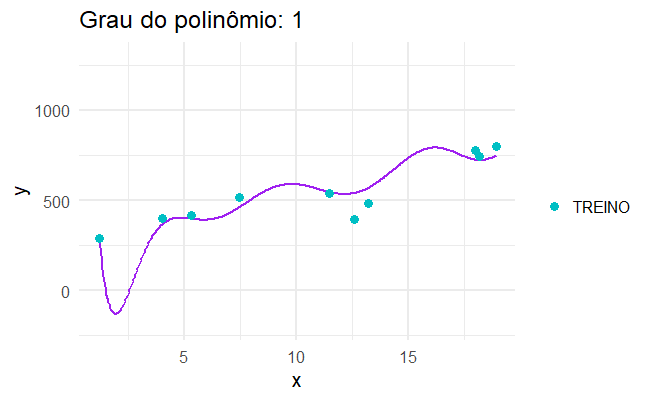
Sobreajuste
…mas quando aplicamos isso no mundo real, os modelos mais complicados não são necessariamente os melhores.
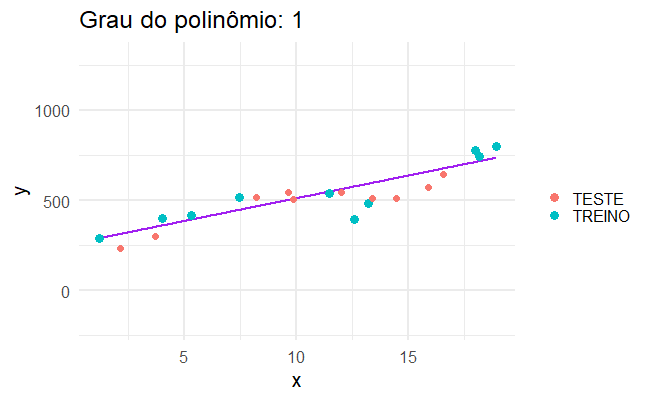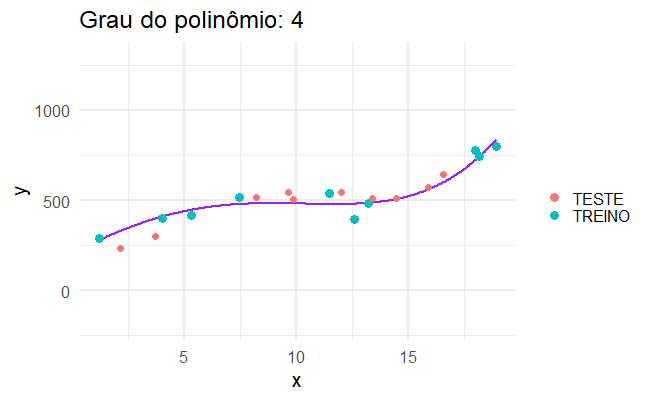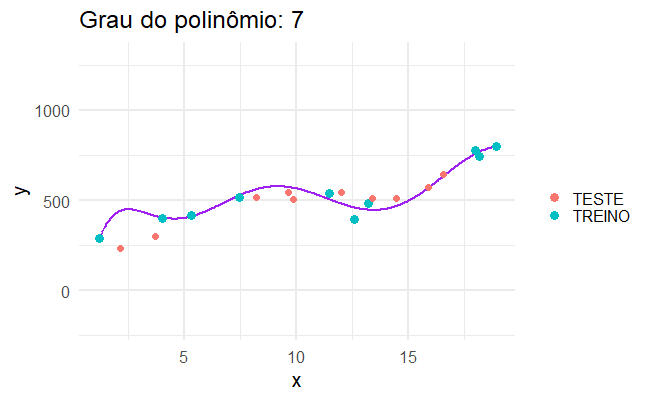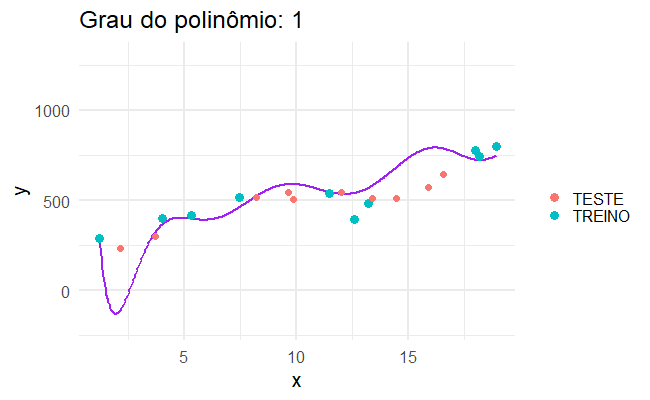
Erro de generalização
Um modelo de aprendizado estatístico precisa funcionar bem para bases de dados que nós não observamos. Para isso, tentamos criar um modelo que se adeque bem aos dados que temos, mas que também funcione bem para dados que não temos.
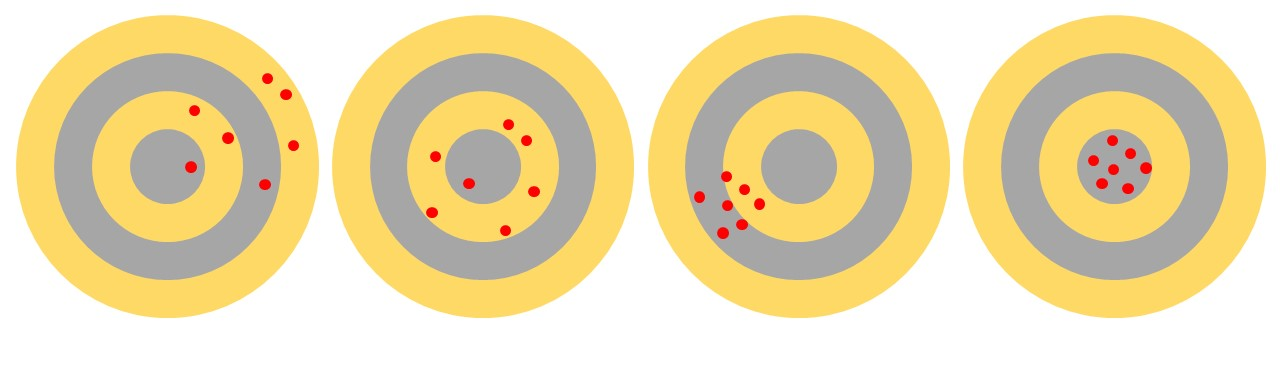
Exemplo
Se quiser acessar o código, entre aqui:

chatGPT
chatGPT é uma interface que usa o modelo GPT. Ela pode entender e responder a perguntas, realizar tarefas como extração de texto e até simular diálogos em cenários específicos.

Um mundo novo
As aplicações de GPT aparecem todos os dias. Vamos ver 3 exemplos:
- Extração de informações
- Análise de jurisprudência
- Geração de textos

Vamos ao R!
Se quiser acessar o código, entre aqui:
O problema da validação
Os textos que saem do GPT podem ser difíceis de validar, pois a resposta “verdadeira” pode ser escrita de diferentes formas.
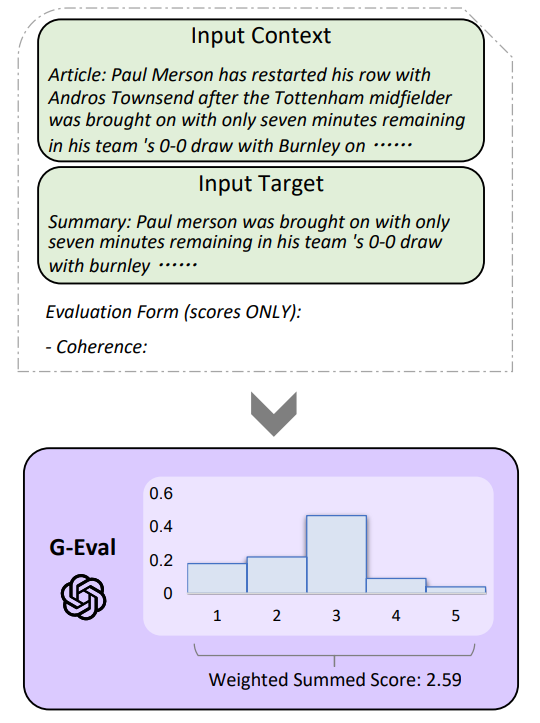
O problema dos grandes documentos
A capacidade de processamento e a limitação de tokens do GPT-4 podem ser desafiadoras ao lidar com documentos extensos.
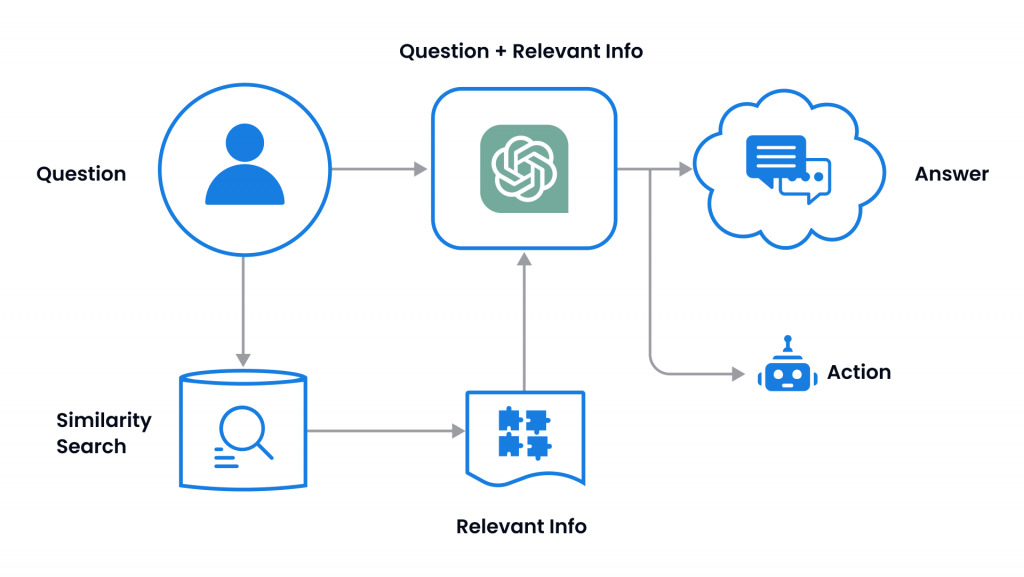
O problema da privacidade: LGPD
O tratamento de dados sensíveis deve estar em conformidade com regulamentações de privacidade, como a LGPD no Brasil.
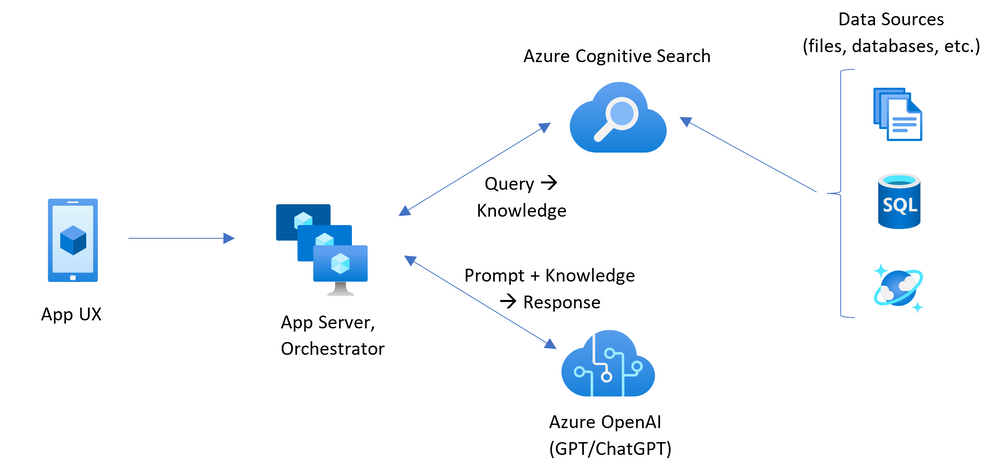
O problema do código fechado
A falta de transparência em como os modelos de IA são treinados e funcionam pode ser um problema em termos de confiabilidade e responsabilização.

O problema do mercado
A pressão por resultados rápidos pode levar a adoção apressada de tecnologias, sem a devida validação e testes.

Imagem de Allison Horst
Solução: RESPIRE!