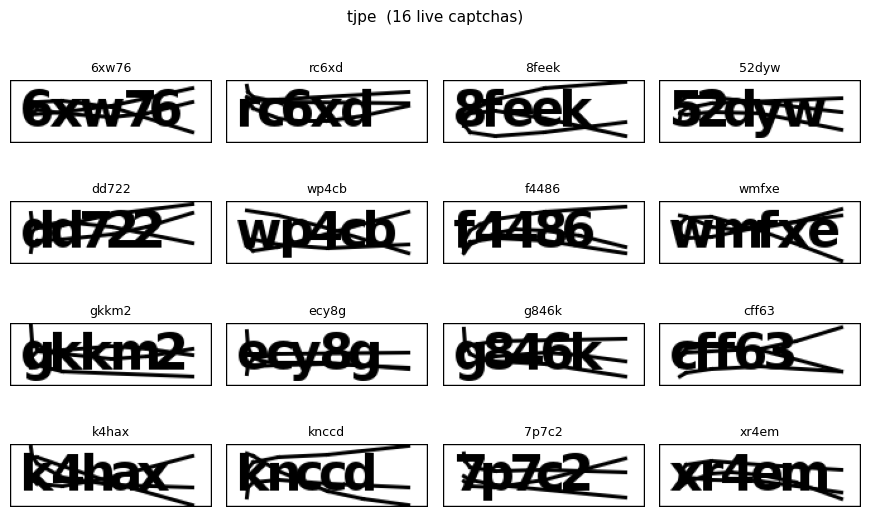
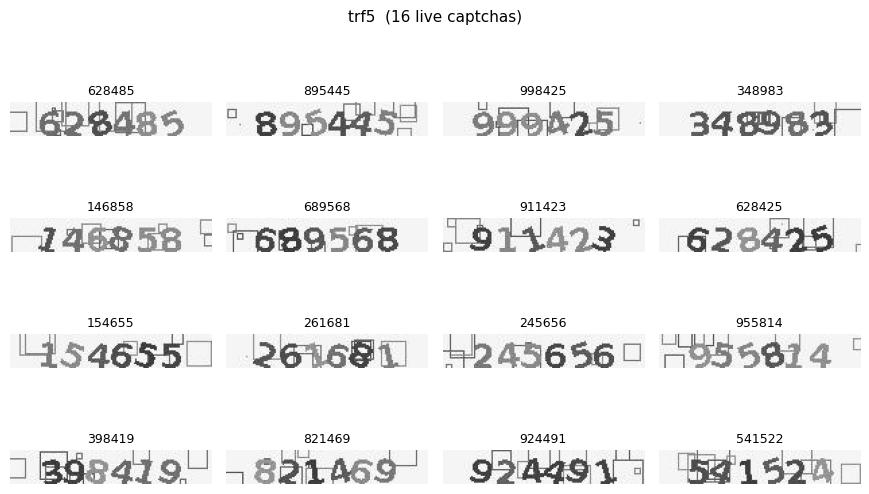
Runs the unified CRNN checkpoint against freshly downloaded captchas from each source in txtcaptcha.download.available_sources(). The live images are never seen during training, so this is the real generalization test — any source with a label accuracy that drops here vs. eval_per_dataset.ipynb was overfitting to the training corpus.
We have no ground-truth labels for these live captchas, so this notebook only shows images with the model’s predictions — no accuracy numbers. Sources that are down or have no downloaded files are skipped with a warning.
Step 1 — Download fresh captchas
Run the command below in a shell (or keep the code cell as-is — it invokes the same CLI entry point from Python). It creates one subdirectory per source under data_live/.
download_captchas--source all --n 16 --dest notebooks/data_live
Some sources may be temporarily unreachable or have changed their markup — those will be skipped with a warning and the notebook simply shows fewer rows for them.
from pathlib import Pathfrom txtcaptcha import available_sources, download_captchasDATA_LIVE = Path('data_live')N_PER_SOURCE =16for src in available_sources(): target = DATA_LIVE / src existing =list(target.glob('*')) if target.exists() else []iflen(existing) >= N_PER_SOURCE:print(f'[{src}] already has {len(existing)} files — skipping download')continueprint(f'[{src}] fetching up to {N_PER_SOURCE}') saved = download_captchas(src, N_PER_SOURCE, target, timeout=20.0)print(f'[{src}] saved {len(saved)}')
[cadesp] already has 16 files — skipping download
[esaj] fetching up to 16
from txtcaptcha import load_model, read_captcha, decryptMODEL_PATH = Path('txtcaptcha_unified.pt')model = load_model(MODEL_PATH)model.eval()print(f'Loaded model with vocab size {len(model.vocab)}')
import matplotlib.pyplot as plt_IMG_EXTS = {'.png', '.jpg', '.jpeg', '.bmp', '.gif', '.tiff', '.webp'}def list_live_files(src: str) ->list[Path]: root = DATA_LIVE / srcifnot root.exists():return []returnsorted(p for p in root.iterdir() if p.suffix.lower() in _IMG_EXTS)def show_live(src: str, cols: int=4): files = list_live_files(src)ifnot files:print(f'[{src}] no live captchas found — skipping')returnNone cap = read_captcha(files) preds = decrypt(cap, model, case_sensitive=False, length=captcha_length[src]) rows = (len(cap) + cols -1) // cols fig, axes = plt.subplots(rows, cols, figsize=(cols *2.2, rows *1.4)) axes = axes.flatten() ifhasattr(axes, 'flatten') else [axes]for ax, img, pred inzip(axes, cap.images, preds): ax.imshow(img) ax.axis('off') ax.set_title(pred, fontsize=9)for ax in axes[len(cap):]: ax.axis('off') fig.suptitle(f'{src} ({len(cap)} live captchas)', fontsize=11) fig.tight_layout()return figfor src in available_sources(): show_live(src)plt.show()
[esaj] no live captchas found — skipping
[rfb] no live captchas found — skipping
[sei] no live captchas found — skipping
[tjrs] no live captchas found — skipping
[trt] no live captchas found — skipping