Resolvendo Captchas
usando Raspagem de Dados e Aprendizado Fracamente Supervisionado

Instituto de Matemática e Estatística
Universidade de São Paulo
Resumo
- Queremos resolver Captchas:
 ->
-> "1158" - Criamos uma nova técnica para isso!
- A proposta une conceitos de raspagem de dados e aprendizado fracamente supervisionado
- A técnica baixa dados da internet e usa os dados para treinar o modelo
- Os resultados são bons!
- Criamos um novo pacote em R, bases de dados públicas e modelos para incentivar pesquisas na área!
O que é Captcha?
- Completely Automated Public Turing Test to Tell Computers and Humans Apart
- O desafio deve ser fácil de resolver para humanos, mas difícil para máquinas
- Criado em 2002 em Carnegie Mellon
- É uma variação do teste de Turing: a avaliação da humanidade é feita pelo robô
Nosso foco está em Captchas de texto em imagem, porque é um dos mais utilizados em serviços públicos.

O mercado de Captcha explora pessoas
- Captchas
impedemespecializam o acesso automatizado - É possível passar a imagem do Captcha para outra pessoa resolver…

Oráculo: a oportunidade
- Quando preenchemos um Captcha no site, ele nos diz se acertamos ou não
- Mas a informação é limitada: o site só diz de acertamos ou erramos.
- É como um oráculo, que sempre nos diz verdade, mas de forma incompleta.

Como funciona?
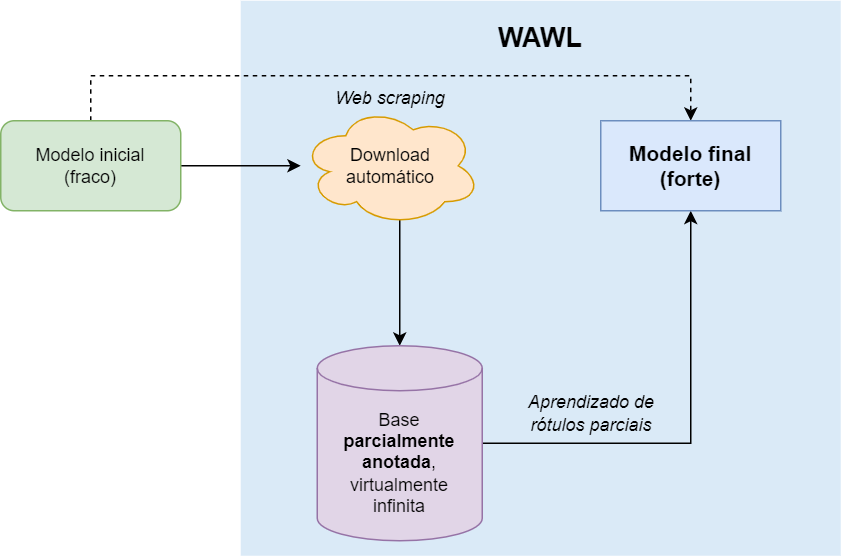
- Modelo inicial: pode ser ajustado com uma pequena base completamente anotada ou pode ser um super-modelo generalista.
Lista de Captchas
| Nome | Exemplo | Descrição |
|---|---|---|
| cadesp |  |
Centro de Apoio ao Desenvolvimento da Saude Publica |
| esaj |  |
Tribunal de Justica da Bahia |
| jucesp |  |
Junta Comercial de Sao Paulo |
| rfb |  |
Receita Federal |
| sei |  |
Sistema Eletronico de Informacoes - ME |
| tjmg |  |
Tribunal de Justica de Minas Gerais |
| tjpe |  |
Tribunal de Justica de Pernambuco |
| tjrs | |
Tribunal de Justica do Rio Grande do Sul |
| trf5 |  |
Tribunal Regional Federal 5 |
| trt |  |
Tribunal Regional do Trabalho 3 |
Também consideramos Captchas artificiais, criados diretamente no R.
Resultados do WAWL
Ganho relativo maior que 3x; ganho absoluto de 33%.

Figura 4: Resultados da simulação por captcha, quantidade de tentativas e modelo inicial.
Aplicação iterada
A utilização da técnica levou o modelo a uma acurácia de 100%.

Figura 5: Resultados da aplicação iterativa do WAWL
O resultado sugere que o método WAWL pode ser aplicado iterativamente para aprimorar o aprendizado do modelo.
Aprendizado online
A partir do modelo inicial 11% de acurácia.

Figura 6: Resultados do experimento com aprendizado online
Após 100 épocas, o modelo baixou 6391 imagens e chegou em uma acurácia de 87% na base de teste.
Pacote {captcha}

- Pacote submetido ao Journal of Open Source Software (JOSS).
- Atualmente, é uma revista conceito B1 no sistema Sucupira (CAPES).
- No momento, estão avaliando se o tema está dentro do escopo da revista.
Obrigado!
