2 Metodologia
If machine learning can decipher captchas, what’s next? Toilets that can read our minds?
– ChatGPT
O capítulo foi organizado em três seções: definição do problema, dados e simulações. A primeira mostra a base matemática do problema estudado e as escolhas de sintaxe e terminologias. A segunda descreve as fontes de dados e o processo de coleta, já que a base foi construída totalmente do zero. A terceira mostra como foram conduzidas as simulações para verificar se a solução proposta funciona bem empiricamente.
Na parte de redes neurais, optou-se por trabalhar nas pontes entre os modelos clássicos de estatística e os modelos de redes neurais, mas sem tecer todos os detalhes técnicos que podem ser encontrados em livros didáticos. Antes de 2015, a pesquisa em redes neurais nos departamentos de estatística era uma novidade, sofrendo até certo preconceito por ser uma classe de modelos “caixa preta”. Com o passar do tempo, no entanto, a área está ficando cada vez mais popular. Por isso, optou-se por trazer poucos detalhes da área, focando nas pontes entre os modelos clássicos e as redes neurais. Espera-se que o conteúdo possa ser aproveitado por pessoas interessadas em ensinar redes neurais para estudantes de estatística.
Na seção de dados, procurou-se apresentar a metodologia de coleta de dados de forma detalhada. Isso foi feito porque a área de raspagem de dados não é comum para estudantes de estatística, existindo até uma percepção entre acadêmicos de que se trata de uma área separada da estatística. Uma das hipóteses de pesquisa, bem como a solução técnica apresentada neste trabalho é justamente que existe uma ponte entre as duas áreas, justificando um detalhamento maior dos conceitos.
Implementações de raspagem de dados, no entanto, são inconstantes. Um site de interesse pode mudar sua estrutura ou simplesmente trocar o Captcha para um reCaptcha, alterando completamente o fluxo de coleta. Isso aconteceu, inclusive, com um dos sites mais importantes dentro do contexto da jurimetria: em 2018, o Tribunal de Justiça de São Paulo (TJSP) passou a utilizar o reCaptcha v2 para bloquear ferramentas automatizadas. Qualquer código ou fluxo para acessar as fontes de dados consideradas no trabalho, portanto, estariam datadas no momento da publicação. Por isso, optou-se por apresentar essa parte de forma genérica e deixar as atualizações para os códigos, que estão disponíveis publicamente e serão mantidos com contribuições da comunidade.
Na seção de simulações, procurou-se descrever todos os passos em detalhe. Nesse caso, a escolha do detalhamento se deu por motivos puramente científicos, para que qualquer pessoa possa reproduzir o que foi feito. Dessa forma, pessoas interessadas na área podem replicar os resultados em outros exemplos com alterações mínimas no fluxo, além de sugerir melhorias.
Definição do problema
O problema a ser trabalhado é um caso de aprendizado fracamente supervisionado (ZHOU, 2018). Trata-se de uma generalização do aprendizado supervisionado e do aprendizado semi-supervisionado. Usualmente, a área de aprendizado estatístico (ou aprendizado de máquinas) se concentra em dois tipos de problemas principais: o aprendizado supervisionado e o aprendizado não supervisionado. Isso ocorre principalmente por fins didáticos, pois é mais fácil passar os modelos que fazem parte de cada área.
No entanto, a estatística evolui com os problemas que ocorrem no mundo. No mundo, os problemas nem sempre recaem em uma ou outra categoria. O que temos, na verdade, é que os problemas não supervisionados e supervisionados estão conectados quando o objetivo da pesquisa é predizer valores (regressão) ou categorias (classificação).
Nesse sentido, uma área que ficou popular nos últimos anos, até por conta dos avanços na área de deep learning, é o aprendizado semi-supervisionado (ZHU, 2005). Trata-se de uma classe de problemas contendo uma amostra completamente anotada e uma amostra sem anotações. A amostra sem anotações é usada para compreender como os dados foram gerados, e os parâmetros podem ser compartilhados com a parte supervisionada do modelo. Isso poderia indicar que existem três classes de problemas: o não supervisionado, o supervisionado e o semi-supervisionado.
Mas isso também não representa todas as classes de problemas. Em muitas aplicações reais, obter uma anotação completa e correta pode ser custoso ou até impraticável. Além disso, por envolver trabalho humano, é comum que classificações contenham erros. A área que generaliza os casos anteriores é o aprendizado fracamente supervisionado.
Aprendizado fracamente supervisionado é um termo guarda-chuva. Dentro da área existem diversos tipos de problemas, como aprendizado semi-supervisionado, aprendizado de múltiplas instâncias (BLUM; KALAI, 1998) e o aprendizado com rótulos incorretos ou incompletos (ZHOU, 2018). O método WAWL é um exemplo de aplicação de uma classe chamada aprendizado com rótulos parciais (partial label learning, PLL, JIN; GHAHRAMANI (2002)). Essa classe apresenta uma especialização ainda mais próxima do problema estudado, chamado aprendizado com rótulos complementares (complementary label learning, ISHIDA et al. (2017)).
A interpretação do Captcha como um problema de PLL será apresentada no final do capítulo. A jornada começa descrevendo um pouco melhor os Captchas, que são o objeto de análise do trabalho.
Captcha
Captcha é um desafio do tipo desafio-resposta usado para determinar se o usuário do sistema é um humano. Existem diversos tipos de Captcha diferentes, que envolvem a identificação de textos em imagens até a resolução de expressões matemáticas complexas.
O foco deste trabalho reside nos Captchas baseados em imagens rotuladas, que é o tipo mais comum. Em seguida, a menos que se mencione ao contrário, todas as menções a Captchas se referem a este tipo.
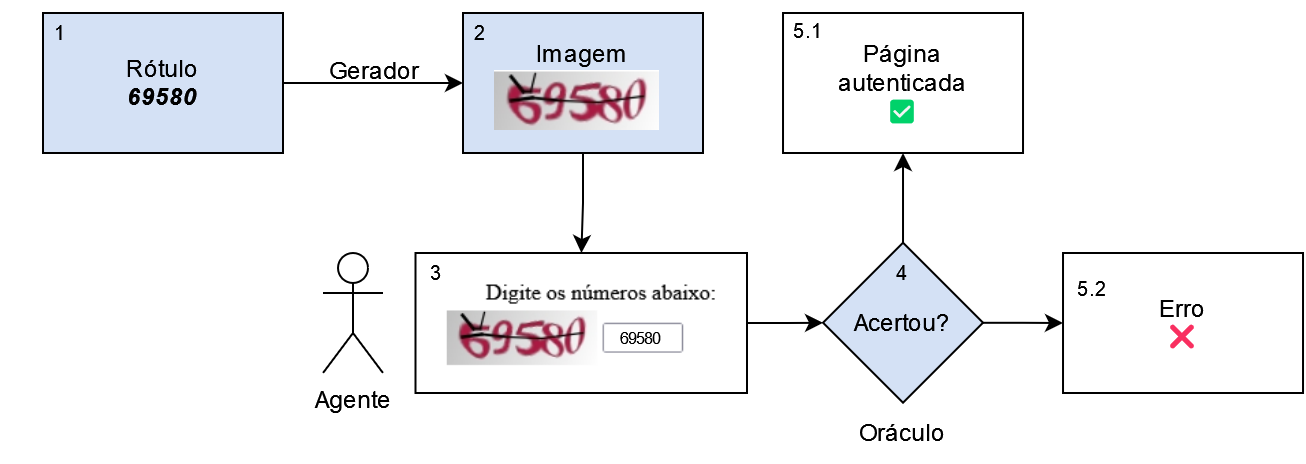
O fluxo completo de um Captcha envolve cinco componentes: um rótulo, um gerador, uma imagem, um agente e um oráculo. O ciclo de um Captcha é completado ao seguir os passos:
- O rótulo (segredo) é definido, usualmente com algum procedimento aleatório, ocultado do agente.
- A imagem é gerada a partir do rótulo e apresentada para o agente.
- O agente produz uma ou mais respostas a partir da imagem (que pode estar certa ou errada)
- O oráculo verifica se a resposta está correta.
- Dependendo da resposta, o agente é direcionado para a página autenticada ou para uma página de erro.
A Figura 2.1 esquematiza o fluxo do Captcha. As caixas com fundo azul são passos realizados pelo servidor, de forma oculta ao agente. As caixas em branco são interações do agente com o site. O agente pode ser tanto um ser humano quanto um robô imitando um ser humano.
Dependendo da forma que um Captcha foi construído, existe a possibilidade de realizar múltiplas tentativas (chutes) para acertar o rótulo. Isso pode ocorrer tanto por uma escolha deliberada dos desenvolvedores do Captcha quanto por falhas na construção do site. A possibilidade de realizar múltiplos chutes pode ter impactos positivos nos resultados do método WAWL, como será visto no Capítulo 3.
Imagem, rótulo e variável resposta
A imagem é uma matriz \(\mathbf x = \{x_{nmr} \in [0,1]\}_{N\times M \times R}\), contendo padrões que levam ao rótulo do Captcha. O rótulo é dado por um vetor de caracteres \(\mathbf c = [c_1,\dots,c_L]^\top\). O comprimento \(L\) pode ser fixo ou variável, ou seja, duas imagens criadas pelo mesmo gerador podem vir com comprimentos diferentes. Nas definições que seguem considerou-se \(L\) como fixo, por simplicidade.
Captchas costumam ter dimensões relativamente pequenas, com a altura \(N\) variando entre 30 e 200 pixels e a largura \(M\) variando entre 100 e 300 pixels. As imagens costumam ser retangulares para comportar várias letras lado a lado, ou seja, geralmente \(M > N\). O valor de \(R\) é 1 para imagens em escala de cinza e 3 para imagens coloridas.
O elemento da matriz \(x_{nm\cdot}\) é denominado pixel. Um pixel é um vetor de comprimento \(R\) que representa a menor unidade da imagem. Em uma imagem colorida, por exemplo, \(R=3\), sendo o pixel um vetor de três dimensões com valores entre zero e um, representando a intensidade de vermelho, verde e azul da coordenada \((n, m)\) da imagem. Em imagens em escala de cinza, \(R=1\) e o pixel, de uma dimensão, representa a intensidade do cinza, sendo 1 o equivalente da cor branca e 0 da cor preta.
Os elementos do vetor \(\mathbf c\) fazem parte de um alfabeto \(\mathcal A\), com cardinalidade \(|\mathcal A|\), finito e conhecido. O alfabeto contém todos os possíveis caracteres que podem aparecer na imagem. Na maioria dos casos, \(\mathcal A\) corresponde a uma combinação de algarismos arábicos (0-9) e letras do alfabeto latino (a-z), podendo diferenciar ou não as letras maiúsculas e minúsculas1.
A Figura 2.2 mostra um exemplo Captcha do Tribunal de Justiça de Minas Gerais (TJMG). Nesse caso, tem-se \(L=5\) e \(|\mathcal A|=10\), apenas os dez algarismos arábicos. A imagem tem dimensões \(N=110\), \(M=40\) e \(R=3\). O rótulo da imagem é \([5,2,4,3,2]^\top\).

A variável resposta é uma matriz binária \(\mathbf y_{L \times |\mathcal A|}\), em que cada linha representa um dos valores do vetor \(\mathbf c\), enquanto as colunas possuem um representante para cada elemento de \(\mathcal A\). Um elemento \(y_{ij}\) vale 1 se o elemento \(i\) do rótulo \(\mathbf c\) corresponde ao elemento \(j\) do alfabeto \(\mathcal A\), valendo zero caso contrário. A variável resposta é uma transformação do rótulo conhecida comumente na área de aprendizado estatístico como one-hot encoding.
Uma maneira alternativa de definir a variável resposta seria com um vetor de índices representando cada elemento do alfabeto em um vetor. O problema de trabalhar dessa forma é que a variável resposta \(\mathbf y\) tem um número exponencial de combinações: o rótulo possui \(L\) caracteres, sendo que cada caractere pode ter \(|\mathcal A|\) valores, totalizando \(|\mathcal A|^L\) combinações. Por exemplo, um Captcha com \(L=6\) letras e \(|\mathcal A| = 36\) possibilidades em cada letra (26 letras do alfabeto latino e 10 algarismos arábicos), possui um total de 2.176.782.336 (\(>\) 2 bilhões) combinações. Por isso, modelar as imagens diretamente através de uma única variável resposta categórica é tecnicamente inviável.
A forma one-hot da resposta pode ser entendida como uma multinomial multivariada (LI; TSUNG; ZOU, 2014). A resposta é multivariada porque existem \(L\) caracteres na imagem e multinomial porque existem \(|\mathcal A|\) possíveis caracteres em cada posição. Dessa forma, é possível pensar que um modelo que resolve o Captcha envolve \(L\) classificadores com resposta multinomial, cada um dando conta de um dos caracteres. Os classificadores podem ser independentes e podem até contar com etapas de pré-processamento separadas.
Seguindo o exemplo da Figura 2.2, é possível representar o rótulo da seguinte forma:
\[ \mathbf c = \left[\begin{array}{c} 5 \\ 2 \\ 4 \\ 3 \\ 2 \end{array}\right] \rightarrow \mathbf{y} = \left[\begin{array}{cccccccccc} 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ \end{array}\right] \]
A forma da variável resposta facilita os trabalhos que seguem. Como será visto mais adiante, o modelo de rede neural gerará uma matriz de probabilidades que somam \(1\) em cada linha, contendo as probabilidades atribuídas a cada caractere nas posições da matriz.
Gerador
O gerador é uma função que recebe um rótulo como entrada e devolve uma imagem como saída. Um bom gerador é aquele que é capaz de gerar uma imagem fácil de interpretar por humanos, mas difícil de interpretar por robôs.
Um exemplo de gerador é a função captcha_generate() criada no pacote {captcha}, que foi descrito em maiores detalhes na Seção 3.2. A função foi criada para realizar simulações do sistema de resolução proposto na tese, a partir do pacote {magick} (OOMS, 2021), que utiliza o software ImageMagick. A função aplica uma série de distorções e efeitos comuns no contexto de Captchas, gerando imagens como a da Figura 2.3.

captcha::captcha_generate()O gerador segue os passos abaixo, a partir do momento em que um rótulo \(\mathbf c\) existe:
- É criada uma matriz \(N\times M \times R\), com valores entre zero e um gerados por simulações de uma \(\mathcal U(0,1)\).
- É adicionada uma cor base ao ruído, definida de forma aleatória.
- A matriz é transformada em um objeto do tipo
magick-image. - A imagem é preenchida com o valor do rótulo, adicionando-se efeitos como rotação, uma linha unindo as letras e variação de cores.
- A imagem recebe outros tipos de distorções, como adição de ruído, alteração de cores e outros efeitos.
No final, o gerador retorna a imagem, que é a única informação enviada ao agente. O rótulo fica escondido para verificação do oráculo.
Oráculo
Para definir o oráculo, utilizou-se uma terminologia que é facilmente encaixada com a teoria de aprendizado fracamente supervisionado. Neste caso, para facilitar a notação, considera-se uma resposta como uma variável multinomial, sem ser multivariada, denotada por \(y\). Seja \(f\) um classificador utilizado para predizer o rótulo de uma imagem e seja \(\mathbf x_{n+1}\) uma nova imagem que é observada, com sua resposta \(y_{n+1}\), desconhecida. A operação \(f(\mathbf x_{n+1})\) retorna um candidato para \(y_{n+1}\), que pode estar correto ou errado.
O oráculo é uma função \(\mathcal O: \mathcal Y \rightarrow 2^{\mathcal Y}\), que recebe um elemento do domínio da resposta \(\mathcal Y\) (do conjunto de todas as combinações de rótulos) para o conjunto de subconjuntos (partes) de \(\mathcal Y\). Na prática, a função retorna uma lista de possíveis valores de \({y}_{n+1}\), da seguinte forma:
\[ \mathcal O(f(\mathbf x_{n+1})) = \left\{\begin{array}{ll} \{ y_{n+1}\}, & \text{ se } y_{n+1} = f(\mathbf x_{n+1}) \\ \mathcal Y \setminus \{f(\mathbf x_{n+1})\}, & \text{ se } y_{n+1} \neq f(\mathbf x_{n+1}) \end{array}\right.. \]
Quando o classificador \(f\) acerta o rótulo, o oráculo retorna o valor “1”, acompanhado de uma lista que contém apenas um elemento: o próprio rótulo. Quando o classificador \(f\) retorna o rótulo errado, o oráculo retorna o valor “0”, acompanhado de uma lista com todos os outros possíveis rótulos do rótulo, o que inclui o verdadeiro valor \(y_{n+1}\). Para simplificar a notação, também é possível chamar essa informação como o rótulo complementar \(\bar{\mathbf y} = \mathcal Y \setminus \{ \hat {y}_{n+1}\}\). Neste caso utiliza-se o símbolo \(\bar{\mathbf y}\), indicando que é uma lista valores possíveis de \(y\).
A Figura 2.4 mostra o funcionamento do oráculo no exemplo do TJMG. Quando a predição é igual ao rótulo, o resultado apresentado é o valor “1”, indicando que o rótulo está correto. Quando a predição é diferente do rótulo, o resultado apresentado é o valor “0”, indicando que o valor testado está incorreto e que, portanto, o rótulo real é um dentre todos os outros possíveis rótulos.

É possível generalizar naturalmente o oráculo para Captchas que aceitam múltiplos chutes mudando a definição da função que faz predições. Seja \(\mathbf f\) uma função que retorna um conjunto de \(k\) respostas possíveis, \(k\in \mathbb N\), \(k\geq 1\), com \(\mathbf x_{n+1}\) e \(y_{n+1}\) iguais aos definidos anteriormente. Então o oráculo tem o funcionamento definido abaixo:
\[ \mathcal O(\mathbf f(\mathbf x_{n+1})) = \left\{\begin{array}{ll} \{y_{n+1}\}, & \text{ se } y_{n+1} \in \mathbf f(\mathbf x_{n+1}) \\ \mathcal Y \setminus \mathbf f(\mathbf x_{n+1}), & \text{ se } y_{n+1} \notin \mathbf f(\mathbf x_{n+1}) \end{array}\right.. \]
Nesse caso, o oráculo também retorna uma lista contendo a resposta \(y_{n+1}\), além de outros valores. A única diferença é que, quando o Captcha aceita múltiplos chutes, a lista retornada em caso de erro tem um comprimento menor.
O oráculo tem um papel fundamental na elaboração do método WAWL. O fato do oráculo sempre retornar a resposta correta na lista de opções faz com que ele necessariamente reduza o espaço de respostas a serem buscadas em uma tentativa futura.
Fatos estilizados dos Captchas
Abaixo, listou-se três características e discussões comuns no contexto dos Captchas, chamados fatos estilizados. Estes pontos vão além da evolução histórica dos Captchas e ajudam a contextualizar melhor o problema.
Uma alternativa para resolver Captchas é separando o problema em duas tarefas: segmentar e classificar. A tarefa de segmentação consiste em receber uma imagem com várias letras e detectar pontos de corte, separando-a em várias imagens de uma letra. Já a classificação consiste em receber uma imagem com uma letra e identificar o caractere correspondente. Nesse caso, a resposta é reduzida para \(|\mathcal A|\) categorias. Como \(|\mathcal A|\) cresce linearmente, o problema é tratável pelos algoritmos tradicionais de aprendizado.
A tarefa de resolver Captchas também poderia ser vista como um problema de reconhecimento óptico de caracteres (Optical Character Recognition, OCR). No entanto, as distorções encontradas em Captchas são bem diferentes das distorções encontradas em textos escaneados, que são o objeto de aplicação de ferramentas de OCR. Por esse motivo, as ferramentas usuais de OCR apresentam resultados pouco satisfatórios em vários Captchas.
As distorções encontradas em Captchas podem ser agrupadas em distorções para dificultar a segmentação e distorções para dificultar a classificação. Na parte de classificação, as principais formas de dificultar o trabalho dos modelos são i) mudar as fontes (serifa ou sem serifa ou negrito/itálico, por exemplo), ii) mudar letras minúsculas para maiúsculas e iii) adicionar distorções nos caracteres. Já na parte de segmentação, as principais formas são i) colar os caracteres e ii) adicionar linhas ligando os dígitos. Essas técnicas são combinadas com a adição de ruído e distorção nas imagens completas para compor a imagem final.
Redes neurais
O método WAWL apresentado na Seção 2.2 utiliza uma arquitetura básica de redes neurais convolucionais. Por isso, é importante apresentar as definições sobre redes neurais e sobre a operação de convolução no contexto de Captchas.
O método WAWL pode utilizar diversas arquiteturas de redes neurais. A escolha de uma arquitetura mais simples foi feita para demonstrar a eficácia do procedimento de forma mais contundente. Outras arquiteturas mais rebuscadas, como as apresentadas na introdução (GEORGE et al., 2017; YE et al., 2018) podem melhorar os resultados do modelo. A única restrição é que ela possa receber uma função de perda modificada, como será mostrado na na Seção 2.2.
A seguir, apresenta-se como funcionam as redes neurais no contexto de Captchas. O modelo descrito é o que foi utilizado nas simulações, que é um modelo de redes neurais convolucionais simples, similar ao LeNet, com três camadas convolucionais e duas camadas densas (LECUN et al., 1998).
É possível organizar a estrutura de uma rede neural em três componentes: a arquitetura da rede, a função de perda e o otimizador. Os componentes são detalhados nas próximas subseções.
Como uma rede neural possui muitos componentes e subcomponentes, é usual apresentar sua estrutura na forma de um diagrama. Redes neurais costumam ser fáceis de representar através de grafos, que podem ser utilizados de forma mais ou menos detalhada, dependendo do interesse.
A Figura 2.5 mostra, de forma esquemática, os componentes (retângulos tracejados) e subcomponentes (partes internas dos componentes) do modelo utilizado. As partes de fora dos componentes são entradas de dados ou decisões de parada do ajuste.

Arquitetura da rede
A arquitetura da rede é uma função que leva os dados de entrada na estrutura de dados (dimensões) da variável resposta. A arquitetura tem papel similar ao exercido pelo componente sistemático em um modelo linear generalizado (NELDER; WEDDERBURN, 1972). Trata-se da parte mais complexa da rede neural, carregando todos os parâmetros que serão otimizados.
A arquitetura da rede possui três componentes principais, com algumas subdivisões:
- as camadas ocultas: camadas convolucionais e camadas densas;
- as técnicas de regularização: normalização em lote (batch normalization), dropout e junção de pixels (max pooling);
- as funções de ativação: função de ativação linear retificada (rectified linear unit, ReLU) e a função de normalização exponencial (softmax).
Abaixo, apresenta-se as definições seguindo-se a ordem de aplicação das operações na arquitetura da rede neural: camada convolucional, ReLU, max pooling, batch normalization, dropout, camada densa e softmax.
A convolução é uma operação linear que recebe como entrada uma matriz e retorna outra matriz. Ela é diferente de uma operação usual de multiplicação de matrizes vista no contexto de modelos lineares generalizados, por envolver uma soma ponderada dos elementos na vizinhança de cada pixel.
Uma forma organizada de fazer a soma ponderada da convolução é criando uma matriz de pesos. Com ela, não é necessário procurar os pontos da vizinhança. Para cada ponto \((i,j)\), obtém-se a matriz de vizinhança, multiplica-se pontualmente pela matriz de pesos e soma-se os valores resultantes. A matriz de pesos é chamada de núcleo, ou kernel.
Considere o kernel
\[ K = \left[\begin{array}{rrr}-1&-1&-1\\0&0&0\\1&1&1\end{array}\right] \]
e a imagem da Figura 2.6. Como visto anteriormente, trata-se de uma matriz de dimensão \(40\times110\times3\).
Tome por exemplo a primeira dimensão do pixel \((n,m,r) = (12,16,1)\). A vizinhança 3x3 em torno desse ponto é dada por
\[ P_{n,m,r} = \left[\begin{array}{rrr} 0.094 & 0.412 & 0.686 \\ 0.051 & 0.063 & 0.529 \\ 0.071 & 0.000 & 0.086 \end{array}\right]. \]
A operação de convolução é feita da seguinte forma:
\[ \begin{aligned} (P_{12,16,1} *K )_{12,16,1} &= k_{1,1}p_{11,15,1} + k_{1,2}p_{11,16,1} + k_{1,3}p_{11,17,1} + \\ &+ k_{2,1}p_{12,15,1} + k_{2,2}p_{12,16,1} + k_{2,3}p_{12,17,1} + \\ &+ k_{3,1}p_{13,15,1} + k_{3,2}p_{13,16,1} + k_{3,3}p_{13,17,1} \\ & = -1.035. \end{aligned} \]
Esse é o valor resultante da convolução, a ser colocado no ponto \((i,j,k)\). A operação funciona da mesma forma em todos os pontos que não estão na borda da imagem.
Existem duas formas de trabalhar com as bordas da imagem. A primeira é preenchendo as bordas com zeros, de forma a considerar apenas os pontos que estão na imagem na conta. A segunda é descartar os pontos da borda e retornar uma imagem menor, contendo somente os pixels em que foi possível aplicar todo o kernel.
No caso do exemplo, o resultado da convolução fica como na Figura 2.7. Como a imagem resultante tem apenas uma dimensão, ela aparenta ficar em preto e branco. Na prática, no entanto, serão aplicados vários núcleos diferentes, resultando em uma imagem com várias cores, que são chamados de canais.
A matriz de exemplo não foi escolhida por acaso: ela serve para destacar padrões horizontais da imagem. Como a primeira linha é formada por \(-1\) e a última é formada por \(1\), a matriz fica com valor alto se a parte de cima do pixel for preta e a parte de baixo for branca (\(\text{grande} * 1 + \text{pequeno} * (-1)\)). A parte destacada da imagem acabou sendo a parte de baixo dos números e, principalmente, a linha que une os números.

Aplicando o kernel vertical abaixo
\[ K = \left[\begin{array}{rrr}-1&0&1\\-1&0&1\\-1&0&1\end{array}\right], \]
as partes destacadas são as laterais dos números, conforme Figura 2.8.

O resultado da convolução pode ter números negativos ou maiores que um. Para que seja possível visualizar, os números das imagens mostradas acima foram ajustados para que ficassem no intervalo \([0,1]\).
Uma característica das imagens mostradas acima é que elas ficaram escuras, ou seja, com muitos valores próximos de zero. Uma técnica para modificar a imagem é adicionar uma constante numérica ao resultado da convolução. Esse é o chamado viés (bias) da convolução.
A Figura 2.9 mostra o efeito de adicionar um viés de 0.6 após aplicação da convolução com kernel vertical. É possível identificar claramente a diferença entre os números (mais suaves) e as curvas usadas para conectar os números (mais proeminentes).

Uma camada convolucional envolve a aplicação de convoluções com \(d\) kernels em uma matriz, além da adição do bias. Tais kernels, bem como o intercepto, terão seus valores ajustados ao longo do processo de otimização do modelo. O resultado da aplicação de uma camada convolucional com preenchimento das bordas é uma matriz com as mesmas dimensões \(N\) e \(M\) da matriz de entrada, mas com \(d\) entradas na dimensão das cores. Como o valor de \(d\) pode ser diferente de 1 ou 3, não faz mais sentido tratar essa dimensão como responsável pelas cores. Por isso essa dimensão é chamada de canais da matriz resultante.
A Figura 2.10 mostra a aplicação de uma camada convolucional para a imagem utilizada nos exemplos anteriores. Os kernels foram escolhidos com base em um modelo que já foi ajustado para o Captcha. Note que os canais capturam a informação dos números e dos ruídos, focando em detalhes diferentes.

Antes da aplicação da camada convolucional, a operação de batch normalization é aplicada. Essa operação normaliza os números da matriz de entrada antes da aplicação da convolução, retirando a média e dividindo pelo desvio padrão, conforme equação abaixo.
\[ x_z = \left(\frac{x-\bar x}{\sqrt{\sigma^2_x + \epsilon}}\right) \gamma + \beta \]
Na equação acima, o valor \(\epsilon\), geralmente um valor pequeno, é adicionado para evitar problemas numéricos quando a variância é muito baixa. Os parâmetros \(\gamma\) e \(\beta\) podem ser adicionados no passo da normalização, fazendo parte do fluxo de aprendizagem do modelo. Apesar de não ser uma teoria fechada, alguns resultados indicam que o uso de batch normalization reduz o tempo de aprendizado dos modelos (IOFFE; SZEGEDY, 2015). O passo foi adicionado nos modelos por apresentar bons resultados nas simulações.
Após a aplicação da convolução, também é aplicada a função não linear ReLU. A transformação ReLU é a mais simples das funções da ativação na teoria de redes neurais, sendo igual à função identidade quando a entrada é positiva e zero caso contrário:
\[ \text{ReLU}(x) = xI_{(x>0)}. \]
A função ReLU serve para tornar a arquitetura do modelo uma operação não linear. Qualquer operação não linear poderia ser utilizada, mas a mais simples e mais popular é a ReLU.
Em seguida, aplica-se uma operação para reduzir a dimensão da imagem, chamada max pooling. Trata-se de uma operação que recebe a imagem e um kernel, retornando, para cada janela, o maior valor dos pixels presentes neste kernel. Usualmente, a técnica também utiliza strides, pulando as interseções entre janelas e fazendo com que cada pixel seja avaliado apenas uma vez. Por exemplo, para uma matriz com dimensões \(M_{10\times10}\) e kernel com dimensões \(2\times2\), aplica-se uma redução pelo fator de \(2\) tanto nas linhas quanto nas colunas, resultando em uma matriz \(M^p_{5\times5}\), onde cada elemento é o valor máximo de cada janela \(2\times2\) correspondente ao pixel.
A Figura 2.11 mostra um exemplo de operação max pooling aplicada ao Captcha. É possível notar que a imagem fica simplificada se comparada com a original. A operação max pooling é muito comum no contexto de redes neurais convolucionais, pois permite que os kernels sejam aplicados em diferentes níveis de zoom da imagem de entrada.

A aplicação das camadas convolucionais é repetida três vezes. Ou seja, as seguintes operações são aplicadas a partir da imagem original:
- batch normalization: 6 parâmetros
- camada convolucional: 896 parâmetros
- ReLU
- max pooling
- batch normalization: 64 parâmetros
- camada convolucional: 18.496 parâmetros
- ReLU
- max pooling
- batch normalization: 128 parâmetros
- camada convolucional: 36.928 parâmetros
- ReLU
- max pooling
- batch normalization: 128 parâmetros.
A dimensão da imagem de entrada, bem como quantidade de canais gerados por cada camada convolucional foram fixadas. Tais números podem ser considerados como hiperparâmetros do modelo, mas foram fixados para facilitar as simulações, que já contam com diversos hiperparâmetros.
A imagem de entrada foi fixada na dimensão \(32\times192\). O valor foi definido dessa forma porque um dos Captchas de referência, da Receita Federal do Brasil (RFB), possui 6 letras e porque \(32*6=192\). Ou seja, é como se a imagem fosse a colagem lado a lado de 6 imagens \(32\times32\).
A quantidade de canais gerados pelas camadas convolucionais foram fixadas em 32, 64 e 64, respectivamente. Ou seja, a primeira camada convolucional retorna uma imagem com 32 canais, a segunda camada convolucional retorna uma imagem com 64 canais, e a terceira camada convolucional retorna uma imagem com 64 canais. A utilização de números não-decrescentes de canais nas camadas convolucionais é comum (LECUN et al., 1998), bem como a utilização de números que são potências de 2 (LECUN; BENGIO; HINTON, 2015), apesar dessa última escolha não ser necessária. Nesse sentido, um possível valor para a terceira camada era de 128 canais, mas optou-se por 64 canais para que a quantidade de parâmetros não ficasse grande demais, já que isso exigiria mais tempo de computação ou computadores mais poderosos.
O total de parâmetros que podem ser otimizados até o final das camadas convolucionais é 56.646. Esse número pode parecer grande no contexto de modelos estatísticos tradicionais como uma regressão linear, que teria, considerando cada pixel como uma covariável, 4.401 parâmetros (\(40\times110\) e o intercepto). No entanto, é uma quantidade relativamente pequena no contexto de redes neurais. Redes neurais recentes aplicadas a imagens, como o DALL-E 2 possui 3,5 bilhões de parâmetros (RAMESH et al., 2022).
Em seguida, o resultado é transformado para um formato retangular, similar ao que se encontra em modelos de regressão. Aqui, as dimensões da imagem não são mais importantes e os pixels de cada canal são tratados como variáveis preditoras. Esse passo pode ser interpretado da seguinte forma: as camadas convolucionais funcionam como um pré-processamento aplicado às imagens, aplicando uma engenharia de variáveis (KUHN; JOHNSON, 2019). No entanto, trata-se de uma engenharia de variáveis otimizada, já que os parâmetros da operação fazem parte do ajuste do modelo.
Uma vez obtidas as variáveis preditoras com o pré-processamento, é hora de aplicar as camadas densas. Tais camadas são as mais comuns no contexto de redes neurais. Nesse caso, a operação linear aplicada é uma multiplicação de matrizes, similar ao que é feito em um modelo linear generalizado. Na verdade, o componente sistemático de um modelo linear generalizado é equivalente a uma camada densa com a aplicação de viés, com a função de ativação (como, por exemplo, uma ativação sigmoide) fazendo o papel da função de ligação. Na rede neural utilizada no modelo, todas as camadas possuem ativação ReLU, com exceção da última, que utiliza ativação softmax.
Assim como existem os canais das camadas convolucionais, existem os filtros das camadas densas. A quantidade de filtros define a dimensão do vetor de saída. O número de parâmetros da camada densa é igual ao número de itens no vetor de entrada multiplicado pelo número de filtros, somado à quantidade de filtros novamente, por conta do bias. No caso do exemplo, a saída das camadas convolucionais tem dimensão \(2\times22\times64\), ou seja, 64 canais de imagens \(2\times 22\). Com a transformação em vetor, concatenando lado a lado os dados dos canais resultantes, a quantidade de colunas da base passa a ser a multiplicação das dimensões, ou 2.816. No modelo ajustado que foi utilizado como exemplo, aplicou-se 200 filtros na camada densa, totalizando 563.400 parâmetros. Esses parâmetros são os pesos que multiplicam os valores em cada camada convolucional, passando pela função de ativação ReLU e pelas camadas densas. Nas simulações, a quantidade de filtros foi variada para produzir modelos com mais ou menos parâmetros de ajuste.
É no contexto da grande quantidade de parâmetros que entra o conceito do dropout (BALDI; SADOWSKI, 2013). Muitos parâmetros podem levar a sobreajuste do modelo, que acaba precisando de técnicas de regularização para funcionar bem. O dropout é uma regra de regularização simples de implementar, mas que possui boas propriedades de regularização. A técnica consiste em selecionar uma amostra dos parâmetros em uma das camadas e apagá-los, forçando que os valores sejam fixados em zero. Na prática, essa técnica obriga o modelo a ser ajustado de forma que amostras aleatórias dos parâmetros sejam boas para predizer a variável resposta. Quando o modelo é usado para predições, o dropout é desativado e o modelo pode utilizar todos os parâmetros, obtendo-se, na prática, uma média ponderada das predições de cada submodelo.
O primeiro dropout é aplicado após a finalização das camadas convolucionais. Em seguida, vem a primeira camada densa, um ReLU e um batch normalization. Depois, é aplicada mais um dropout e mais uma camada densa. Com isso, a aplicação de operações é finalizada. O total de parâmetros na configuração do modelo apresentado foi de 630.496. Os modelos mais simples utilizados nas simulações, com 100 filtros na camada densa, têm 343.696 parâmetros. Os mais complexos, com 300 filtros na camada densa, têm 917.396 parâmetros.
Para finalizar a arquitetura do modelo, as quantidades resultantes devem ser ajustadas ao formato da variável resposta. O número de filtros da segunda camada densa precisa ser escolhido cuidadosamente, pois deve ser igual à multiplicação das dimensões da variável resposta. No caso do TJMG, os rótulos têm comprimento igual a 5 e vocabulário de comprimento 10 (algarismos arábicos), organizados em uma matriz \(5\times10\), com 50 entradas. Por isso, a quantidade de filtros da última camada densa também é 50, e o vetor de saída é formatado para uma matriz de dimensão \(5\times10\).
No final, o resultado precisa ser normalizado para que fique no mesmo escopo de variação da resposta. A resposta possui apenas zeros e uns, sendo que cada linha da matriz tem somente um número “1”, correspondendo ao índice do rótulo no alfabeto e, nas outras entradas, o valor zero. A saída do modelo deve, portanto, apresentar números entre zero e um que somam 1 em cada linha.
Isso é feito através da função softmax, aplicada a cada linha da matriz de saída. A função softmax é uma normalização que utiliza a função exponencial no denominador, forçando que a soma dos valores do vetor seja um.
\[ \text{soft}\max(y_i) = \frac{e^{y_i}}{\sum_{j=1}^{|\mathcal A|} e^{y_j}}. \]
No exemplo, a saída do modelo é a matriz abaixo:
\[ \hat{\mathbf z} = \left[\begin{array}{rrrrrrrrrr} -17.5 & -13.5 & -15.4 & -6.6 & -9.9 & 9.9 & -11.4 & -10.9 & -11.8 & -9.3 \\ -10.9 & -15.6 & 8.3 & -6.5 & -11.0 & -10.3 & -10.0 & -5.8 & -11.4 & -15.1 \\ -10.5 & -13.6 & -9.6 & -11.4 & 11.2 & -14.3 & -9.9 & -11.3 & -9.9 & -10.0 \\ -18.1 & -9.6 & -10.9 & 5.3 & -10.1 & -6.6 & -15.5 & -13.3 & -6.8 & -10.8 \\ -11.3 & -8.7 & 6.4 & -7.0 & -6.1 & -9.2 & -18.9 & -10.3 & -16.1 & -9.6 \\ \end{array}\right]. \]
Note que a matriz apresenta valores negativos e positivos. Na primeira linha, por exemplo, o valor positivo está na sexta coluna, correspondendo ao algarismo “5”. De fato, esse é o valor do primeiro elemento do rótulo para esta imagem. Após a aplicação do softmax, a matriz de predições obtida é a matriz abaixo2. O modelo de exemplo aparenta ter confiança nas respostas, já que dá probabilidades bem altas para alguns valores e quase zero para outros valores.
\[ \hat{\mathbf Y}\times 1000 = \left[\begin{array}{rrrrrrrrrr} 0.00 & 0.00 & 0.00 & 0.00 & 0.00 & 1000.0 & 0.00 & 0.00 & 0.00 & 0.00 \\ 0.00 & 0.00 & 1000.0 & 0.00 & 0.00 & 0.00 & 0.00 & 0.00 & 0.00 & 0.00 \\ 0.00 & 0.00 & 0.00 & 0.00 & 1000.0 & 0.00 & 0.00 & 0.00 & 0.00 & 0.00 \\ 0.00 & 0.00 & 0.00 & 999.99 & 0.00 & 0.01 & 0.00 & 0.00 & 0.00 & 0.00 \\ 0.00 & 0.00 & 999.99 & 0.00 & 0.00 & 0.00 & 0.00 & 0.01 & 0.00 & 0.00 \\ \end{array}\right]. \]
Vale notar que, dependendo da implementação, nem sempre é necessário aplicar a função softmax. Em alguns pacotes computacionais como o torch3, utilizado nesta tese, a normalização pode ser feita diretamente na função de perda, que aproveita a expressão completa para realizar algumas simplificações matemáticas e, com isso, melhorar a precisão das computações. O uso da função de perda ficará claro na próxima subseção.
Perda
A função de perda utilizada em um problema de classificação deve levar em conta as probabilidades (ou pesos) associadas aos rótulos. A perda deve ser pequena se a probabilidade associada ao rótulo correto for alta e deve ser grande se a probabilidade associada ao rótulo correto for baixa.
Uma função de perda natural e popular nesse sentido é a de entropia cruzada, ou cross-entropy. Trata-se de uma perda com a formulação
\[ \mathcal L(g(x), y) = -\sum_{i=1}^c I(y=i)\log(g_i(x)). \tag{2.1}\]
Na equação, \(g_i(x)\) é a probabilidade dada ao rótulo \(i\) pela função \(g\). Se o rótulo \(i\) é diferente do rótulo correto \(y\), a função de perda vale zero por conta da função indicadora. Quando \(i=y\), a perda é igual ao oposto do logaritmo da probabilidade associada ao rótulo \(i\). Quanto menor a probabilidade, maior o valor da perda.
Ao trabalhar com o oráculo, a entropia cruzada passa a não fazer sentido nos casos em que o modelo inicial erra. Por isso, a função de perda será adaptada no método WAWL. Essa é a única modificação estritamente necessária para aplicar o método.
Otimizador
O otimizador utilizado para os modelos ajustados na tese foi o ADAM (KINGMA; BA, 2017). A sigla significa Adaptive Moment Estimator e funciona como uma extensão da descida de gradiente estocástica (LECUN et al., 2012). Considere que \(\theta\) é o conjunto de todos os parâmetros do modelo, ou seja, os parâmetros das camadas convolucionais, densas e batch normalization. Os parâmetros são atualizados da seguinte forma:
\[ \begin{array}{cl} m_{\theta}^{(t+1)} &\leftarrow \beta_1m_{\theta}^{(t)} + (1-\beta_1)\nabla_\theta \mathcal{L}^{(t)} \\ v_{\theta}^{(t+1)} &\leftarrow \beta_2v_{\theta}^{(t)} + (1-\beta_2)(\nabla_\theta \mathcal{L}^{(t)})^2 \\ \hat{m}_{\theta} &= \frac{m_\theta^{(t+1)}}{1-\beta_1^t} \\ \hat{v}_{\theta} &= \frac{v_\theta^{(t+1)}}{1-\beta_2^t} \\ \theta^{(t+1)} &\leftarrow \theta^{(t)} - \eta \frac{\hat{m}_{\theta}}{\sqrt{\hat{v}_{\theta}} + \epsilon}. \end{array} \]
Na equação, \(m\) e \(v\) são médias móveis para atualização dos parâmetros, ponderando a perda e a perda ao quadrado com o passo anterior usando pesos \(\beta_1\) e \(\beta_2\), respectivamente. Nessa notação \(\eta\) é a taxa de aprendizado, um hiperparâmetro a ser ajustado. Por último, o valor de \(\epsilon\) é uma constante, usualmente pequena, para evitar divisão por zero.
Ainda que o ADAM seja um método adaptativo, pode ser vantajoso considerar uma taxa de decaimento no parâmetro \(\eta\). Esse fator pode ser desnecessário em alguns casos, mas pode auxiliar o modelo a dar passos menores quando o modelo já está com uma acurácia razoável. Neste trabalho, foram consideradas alguns valores de decaimento na taxa de aprendizado, como 1% ou 3% de decaimento ao final de cada época, ou seja, ao final de cada ciclo de particionamento da base.
Aprendizado estatístico
Apresentados o objeto de estudo e as redes neurais utilizadas, passa-se a discutir o significado disso tudo no contexto de aprendizado estatístico. Essa parte foi escrita para proporcionar a base teórica para apresentar o modelo WAWL.
O aprendizado fracamente supervisionado pode ser dividido em três tipos principais. A supervisão com erros, a supervisão com rótulos incompletos e a supervisão de grupos de observações. O caso do Captcha pode ser entendido como uma subárea do aprendizado fracamente supervisionado com rótulos incompletos chamada aprendizado com dados parcialmente rotulados (PLL), já que uma parte da base pode ser anotada sem erros e uma parte da base é a resposta do oráculo indicando uma lista de rótulos possíveis, incluindo o correto.
A área de PLL não é nova (GRANDVALET, 2002) e aparece com outros nomes, como aprendizado com rótulos ambiguos (HÜLLERMEIER; BERINGER, 2006) e aprendizado de rótulos em superconjuntos (superset-label learning) (LIU; DIETTERICH, 2012). Um caso particular de PLL, aplicável ao tema do Captcha são rótulos complementares (ISHIDA et al., 2017), que considera os chutes errados na notação do problema.
As definições seguem uma terminologia adaptada a partir da leitura de JIN; GHAHRAMANI (2002), COUR; SAPP; TASKAR (2011) e FENG et al. (2020a). Sempre que possível, os casos são adaptados para o problema do Captcha diretamente. Para simplificar a notação, no entanto, foi considerado o problema univariado do Captcha, ou seja, como se uma imagem tivesse apenas uma letra. Não há perda de generalidade nessa escolha, já que o problema do Captcha pode ser, de fato, separado em vários problemas, um para cada letra da imagem.
Em um problema de aprendizado supervisionado tradicional, tem-se um conjunto de \(S\) casos rotulados \(\{(\mathbf x_i,y_i), i=1,\dots, S\}\) com uma distribuição \(p(\mathbf x,y)\) desconhecida, onde \(\mathbf x\) é uma imagem e \(y\) é o rótulo, que possui \(|\mathcal A|\) possíveis valores. O objetivo é obter um classificador \(f\) que leva um valor de \(\mathbf x\) para o rótulo correto \(y\).
Para delimitar se o classificador está bom ou ruim, utiliza-se uma função de perda. No caso do Captcha, como o interesse é simplesmente acertar o rótulo inteiro (não importa se o classificador acerta só uma parte do rótulo), utiliza-se uma função chamada 0-1:
\[ \mathcal L(f(\mathbf x),y) = I (f(\mathbf x) \neq y). \tag{2.2}\]
Na equação, \(I(\cdot)\) é uma função indicadora. Como a função de perda é aplicada a apenas um par \((\mathbf x,y)\), define-se que o objetivo do problema de aprendizado é minimizar o risco, que é o valor esperado da função de perda, calculado para as variáveis aleatórias \(\mathbf X\) e \(Y\):
\[ \mathcal R(g) = \mathbb E_{p(\mathbf x,y)}[\mathcal L(g(\mathbf X),Y)]. \tag{2.3}\]
A função de risco, no entanto, não é observada, já que depende da distribuição desconhecida de \(p(\mathbf x,y)\). Por isso, utiliza-se um estimador do risco, que pode ser calculado em uma amostra, como uma base usada na validação cruzada ou na base de teste. Para uma amostra com \(S\) observações, tem-se
\[ \hat{\mathcal R}(g) = \sum_{s=1}^S \mathcal L(g(\mathbf x_s),y_s)) \]
Na base de teste, utilizada para estimar o risco, a função de perda 0-1 é apropriada. Na etapa de validação cruzada de um modelo de aprendizado profundo, é útil considerar uma função de perda que seja contínua e derivável, funcionando como uma versão suavizada da perda 0-1. A partir de um vetor de parâmetros \(\boldsymbol \theta\) originados da arquitetura do modelo, uma escolha de função de perda é a entropia cruzada, como na Equação 2.1. Os parâmetros são estimados a partir de um otimizador, como o ADAM, apresentado na Seção 2.1.2.3.
As definições começam a precisar de ajustes quando \(y\) deixa de ser um rótulo fixado. Como descrito na Seção 2.1.1.3, quando o modelo inicial erra, o que se observa é uma lista de possíveis valores para \(y\), que contém o rótulo correto e outros incorretos. Se o Captcha aceita apenas um chute, essa lista contém todos os possíveis valores do rótulo, menos o valor incorreto que foi utilizado no oráculo. Se o Captcha aceita vários chutes, a lista contém todos os valores possíveis de \(y\) menos os valores que foram testados.
Para isso, utiliza-se a notação do \(\bar {\mathbf y}\). A notação utiliza negrito para enfatizar que o objeto contém uma lista de possíveis valores, e não apenas um valor. Por exemplo, considere \(\mathcal A = \{0,1,\dots,9\}\) um alfabeto com os algarismos de zero até nove, como no MNIST, e um Captcha que aceita múltiplos chutes. Nesse caso, para uma imagem \(\mathbf x\) com rótulo \(3\), seguindo as definições da Seção 2.1.1, o valor de \(y\) seria dado pela matriz
\[ y = [0\;0\;0\;1\;0\;0\;0\;0\;0\;0]. \]
Aqui, o valor \(3\) é colocado na quarta posição da primeira (e única) linha da matriz. Como o problema está sendo trabalhado na forma univariada, para simplificar a notação, pode-se considerar apenas os valores dos rótulos, ou seja, \(y=3\).
Considere, agora, que o modelo inicial produziu as tentativas incorretas \(\mathbf g(\mathbf x) = \{6,8\}\). O valor observado \(\bar{\mathbf y}\) envolve todos os valores de \(y\) menos as tentativas incorretas:
\[ \bar{\mathbf y} = \{0,1,2,3,4,5,7,9\}. \]
Na prática, o que se observa, então, são pares \((\mathbf x,y)\), nos casos corretos, ou pares \((\mathbf x,\bar{\mathbf y})\), nos casos incorretos. Para generalizar a notação, é possível considerar uma variável indicadora de acerto do modelo inicial \(z\) e a lista \(\mathbf y\), definida da seguinte forma:
\[ \mathbf y = \left\{\begin{array}{cl}\{y\}&,\text{ se }z=1\\\bar{\mathbf y}&,\text{ se }z=0\end{array}\right.. \]
Assim, observa-se uma amostra de \(\{(\mathbf x_s,\mathbf y_s, z_s)\}, s = 1,\dots,S\). A distribuição desses dados está diretamente relacionada com a acurácia do modelo inicial. Por exemplo, se o modelo inicial acerta todos os chutes, o resultado será sempre o valor correto \(y\), e o problema recai em um caso supervisionado tradicional. Quando o modelo inicial erra todos os casos, todos os rótulos são parciais e o problema recai em um caso de PLL puro. Na prática, o que se espera é que a amostra tenha uma mistura de rótulos corretos e de rótulos parciais.
É possível desconsiderar o valor \(z\) na notação. Como os rótulos parciais sempre incluem o rótulo correto \(y\), quanto o conjunto contém apenas um elemento, este é o rótulo correto. Ou seja:
\[ z=1 \iff |\mathbf y|=1. \]
Portanto, basta considerar os pares \((\mathbf x_s, \mathbf y_s)\) da amostra para definir o problema. Definida a estrutura de dados da amostra, passa-se a discutir a forma de obter um classificador com boas propriedades.
Uma estratégia eficaz para derivar propriedades de classificadores na área de PLL é escrever a distribuição dos dados de forma explícita (FENG et al., 2020a, 2020b; ISHIDA et al., 2017; YU et al., 2018). A partir dessa distribuição, a função de risco do problema completamente supervisionado é reescrita em termos da função de risco do problema com rótulos parciais. Depois, é criado um estimador para essa função de risco, a partir de uma amostra observada. Finalmente, utilizando funções de perda adequadas, demonstra-se que a função de risco do problema com rótulos parciais se aproxima da função de risco com dados completamente supervisionados, conforme a base de dados aumenta.
A forma mais fácil de definir a distribuição dos dados com rótulos parciais é considerando que os valores dos rótulos parciais aparecem ao acaso. Por exemplo, considere que as imagens são geradas com uma distribuição \(p(\mathbf x, y)\), que não precisa ser conhecida. Então a distribuição dos rótulos parciais \(\tilde p (\mathbf x, \mathbf y)\) é dada por (FENG et al., 2020a):
\[ \tilde p (\mathbf x, \mathbf y) = \sum_{y}p(\mathbf y|y)p(\mathbf x, y), \text{ onde } p(\mathbf y|y)=\left\{\begin{array}{ll}\frac{1}{2^{|\mathcal A|-1}-1},&\text{ se } y\in\mathbf y,\\0,&\text{ se } y\notin \mathbf y\end{array}\right.. \tag{2.4}\]
A distribuição pode ser interpretada da seguinte forma. Os valores possíveis de \(\mathbf y\) são todos os possíveis subconjuntos do alfabeto, menos os casos extremos (vazio e o alfabeto completo). Por exemplo, no caso de um alfabeto com os 10 algarismos, os valores de \(\mathbf y\) podem ser todas as combinações dos algarismos, menos o conjunto vazio e o conjunto \(\{0,\dots,9\}\). Isso dá \(2^{|\mathcal A|}-2\) combinações no total.
Considerando a restrição de PLL de que a resposta \(\mathbf y\) sempre contém o verdadeiro rótulo, é intuitivo que \(p(\mathbf y|y)=0\) quando \(y\notin \mathbf y\). Ou seja, a probabilidade de observar \(\mathbf y\) quando se sabe que o \(y\) correto foi observado e este \(y\) não está no conjunto \(\mathbf y\) é zero. Agora, quando \(y \in \mathbf y\), a probabilidade é calculada considerando todos os possíveis subconjuntos do alfabeto que contêm \(y\), que são \(2^{|\mathcal A|-1}-1\). Por exemplo, de todos os subconjuntos válidos do conjunto \(\{0,\dots,2\}\), ou seja, \(\{0\},\{1\},\{2\}, \{0,1\}, \{0,2\}\) e \(\{1,2\}\), tem-se \(2^{3-1}-1=3\) conjuntos que contêm o valor \(2\). Por isso, a probabilidade atribuída a \(p(\mathbf y|y)\) é uma uniforme, dando pesos iguais para todos os possíveis rótulos.
Uma suposição implícita da distribuição na Equação 2.4 é que \({\mathbf y}\) é condicionalmente independente de \({\mathbf x}\) dado \(y\). Ou seja, para qualquer valor de \(y\),
\[ p(\mathbf y|\mathbf x, y) = p(\mathbf y| y). \]
Essa suposição significa que o valor do rótulo complementar não depende da imagem quando se sabe o rótulo da imagem. No caso dos Captchas, essa suposição é verificada, porque a imagem é simplesmente uma representação do rótulo, então a probabilidade do modelo inicial errar depende apenas do rótulo e não das distorções realizadas pela imagem gerada a partir do rótulo.
Como comentado anteriormente, a partir da distribuição dos dados é possível reescrever a função de risco do problema completamente supervisionado em termos do problema de rótulos parciais (FENG et al., 2020a, eq (6)). A partir de um estimador desse risco, utiliza-se um método de aprendizado de máquinas (como redes neurais) para obter um classificador \(\hat f\). Considerando que \(f^*\) é a função obtida em um problema completamente supervisionado e seguindo algumas suposições adicionais, é possível demonstrar que
\[ |\mathcal R(\hat f) - \mathcal R(f^*)| \] é limitada e converge para zero quando tamanho da amostra vai para infinito. Mais do que isso, é possível obter a taxa de convergência do risco, em função da complexidade de Rademacher. Os detalhes e a demonstração podem ser encontrados no artigo de FENG et al. (2020a).
Nas descrições dadas acima, a única suposição que não é satisfeita é a de que os valores de \(\mathbf y\) são distribuídos uniformemente. Essa suposição é inválida porque os valores observados de \(\mathbf y\) são resultado dos erros do modelo inicial aplicado ao oráculo e porque o número de tentativas geralmente é limitado. Como o modelo inicial não tem distribuição uniforme, o resultado também não é uniforme.
O tipo de problema nesse caso é conhecido como biased partial label (YU et al., 2018). Um dos artigos estudados apresenta uma solução para o caso em que o rótulo parcial é um rótulo complementar (ou seja, quando o Captcha aceita apenas um chute). Nesse caso as probabilidades \(p(\mathbf y| y)\) podem ser organizadas em uma matriz de transição \(\mathbf Q\), contendo as probabilidades de se obter um rótulo incorreto para cada possível valor do rótulo. Para resolver problemas desse tipo, é possível realizar um ajuste na função de predição:
\[ f_{\text{adj}} (\mathbf x) = \mathbf Q ^{\top}f(\mathbf x). \]
O caso do oráculo e dos Captchas é um problema com múltiplos rótulos complementares e com viés. Até o momento, não existe uma solução geral para este tipo de problema. No entanto, espera-se que as soluções para problemas desse tipo tenham taxas de convergência mais estreitas do que o caso de rótulos complementares, com ou sem viés, já que rótulos complementares múltiplos trazem mais informação do que rótulos complementares simples.
Método WAWL
O método WAWL (Web Automatic Weak Learning) é a solução proposta na pesquisa. Trata-se da técnica baixar dados da web para compor parte da amostra que é utilizada no ajuste do modelo.
O método WAWL é inovador por dois motivos. Primeiro, porque o método faz a ponte entre áreas que até o momento eram partes separadas no ciclo da ciência de dados: a raspagem de dados e o aprendizado estatístico. Além disso, o método é uma nova alternativa para resolver Captchas com pouca ou nenhuma intervenção humana.
A Figura 2.12 mostra o funcionamento básico do WAWL. Primeiro, ajusta-se um modelo inicial para o Captcha desejado, que pode ser uma adaptação de modelos existentes ou um modelo construído com base em uma pequena amostra completamente anotada. Em seguida, aplica-se as predições do modelo inicial no oráculo para obter uma nova base de dados parcialmente anotada da internet. Finalmente, um novo modelo é ajustado com os dados obtidos, utilizando uma adaptação na função de perda.
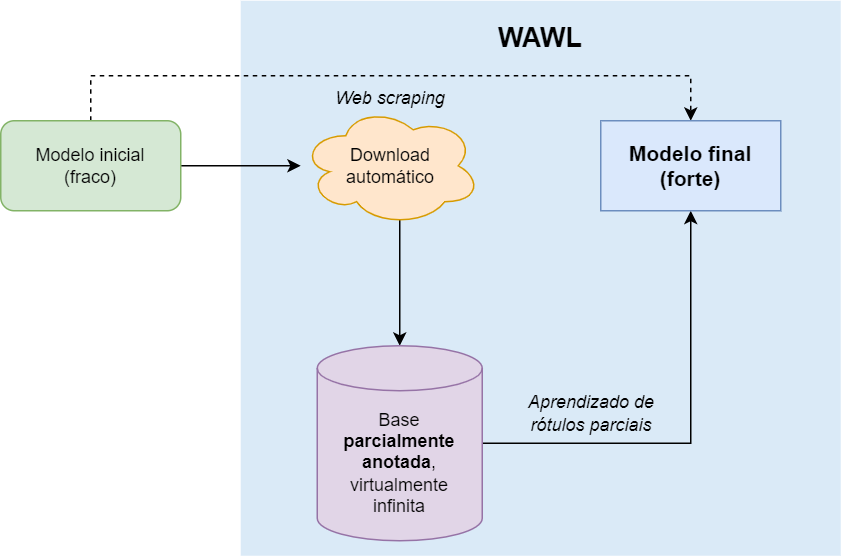
A arquitetura do modelo WAWL pode ser a mesma de um modelo ajustado com uma base completamente anotada. O modelo pode, inclusive, aproveitar os parâmetros já ajustados do modelo inicial, acelerando o aprendizado. Nada impede, no entanto, que uma arquitetura diferente seja utilizada, desde que a entrada seja uma imagem e a saída seja uma matriz com as dimensões da variável resposta. O WAWL é agnóstico à arquitetura do modelo.
A função de perda deve ser adaptada para considerar a informação limitada fornecida pelo oráculo. Quando o rótulo fornecido pelo modelo está correto, a informação é considerada normalmente, através da função de perda da regressão multinomial multivariada. Já quando o rótulo fornecido pelo modelo é incorreto, a função de perda é calculada com base na probabilidade do rótulo estar incorreto:
\[ 1 - p(y|\boldsymbol \theta). \]
Considere o rótulo parcial \({\mathbf y}\) e a função \(g\), dada pela rede neural, que retorna um vetor de probabilidades \([g_y], y \in \mathcal A\). Os valores de \(g_y\) somam 1 e têm os pesos relacionados a cada possível rótulo a partir da imagem \(\mathbf x\). O WAWL modifica a entropia cruzada (função de perda original) nos casos anotados pelo oráculo como errados, e mantém a função de perda original nos casos corretamente anotados. A fórmula para descrever a função de perda modificada é:
\[ \mathcal L(g(\mathbf x), {\mathbf y}) = -\log\left[1 - \sum_{y \in \mathcal A} {g_y}(\mathbf x) I(y\notin {\mathbf y})\right]. \]
Por conta da função indicadora, a perda só é calculada nos pontos que estão de fora do rótulo parcial observado \(\mathbf y\). Ou seja, o valor é calculado somente nos casos que o modelo inicial errou. Outra forma de escrever a mesma função de perda é fazendo:
\[ \mathcal L(g(\mathbf x), {\mathbf y}) = -\log\left[ \sum_{y \in \textbf{y}} g_y(\mathbf x)\right]. \]
A função proposta pode ser explicada de maneira intuitiva através de exemplos. Considere um problema com apenas \(10\) possíveis valores para o rótulo e uma resposta multinomial, sem ser multivariada, como considerado na Seção 2.1.3. Considere também que a rede neural retorna uma alta probabilidade, por exemplo, \(0.99\), para o valor \(j\), que o oráculo identificou como incorreta. Logo, \(\mathbf {\bar y} = \{1,\dots,10\}\setminus \{j\}\), e a função de perda é dada por
\[ \mathcal L(g(\mathbf x), \{1,\dots,10\}\setminus \{j\}) = -\log\left[1-{g_j}(\mathbf x)\right] = -\log\left[1-0.99 \right] = 4.61. \]
Como é possível ver no exemplo, quanto maior a probabilidade dada a um rótulo identificado como incorreto pelo oráculo, mais a função de perda penaliza essa predição. Dessa forma, a função de perda consegue incorporar a informação dada pelo oráculo adequadamente.
Considere, agora, que a rede neural retorna uma probabilidade pequena, por exemplo, \(0.01\), para o valor \(k\), que o oráculo identificou como incorreta. Logo, \(\mathbf {\bar y} = \{1,\dots,10\}\setminus \{k\}\), e a função de perda é um valor pequeno:
\[ \mathcal L(g(\mathbf x), \{1,\dots,10\}\setminus \{k\}) = -\log\left[1-{g_k}(\mathbf x)\right] = -\log\left[1-0.01 \right] = 0.01. \]
Quando o Captcha aceita múltiplos chutes, a mesma conta é válida, bastando subtrair as probabilidades de todos os rótulos incorretos. No final, o valor da função de perda é a soma das perdas para todas as observações do minibatch. A soma considera tanto as perdas calculadas com base nos rótulos corretos quanto as perdas calculadas com base nos rótulos incorretos.
O otimizador que obtém novas estimativas dos parâmetros também não precisa ser modificado. Basta aplicar a mesma técnica utilizada na modelagem usual, como descida de gradiente estocástica ou métodos adaptativos, como o ADAM.
Um detalhe importante sobre o método é sobre a implementação. Com a utilização de ferramentas que fazem diferenciação automática como o torch e o TensorFlow4, basta implementar a parte da arquitetura, a função de perda e especificar o otimizador, já que o processo de atualização dos parâmetros é feito automaticamente. No entanto, dependendo da implementação, não é possível fazer a atualização dos parâmetros usando o componente de computação gráfica, que potencialmente acelera o ajuste dos modelos de forma significativa. Na implementação atual, a função de perda apresentada não permite utilização deste componente, sendo uma melhoria possível em futuros trabalhos.
O ajuste dos modelos, tanto para simulações quanto para construção dos modelos finais, utilizou o pacote {torch} (FALBEL; LURASCHI, 2022), que é uma implementação do PyTorch para a linguagem de programação R (R CORE TEAM, 2021). O pacote {luz} (FALBEL, 2022a) foi utilizado para organizar as funções de perda e hiperparâmetros, enquanto o pacote {torchvision} (FALBEL, 2022b) foi utilizado para utilidades no tratamento de imagens.
Dados
Nesta seção, descreve-se em detalhes como foi a obtenção dos dados para realizar a pesquisa. Como comentado anteriormente, a base foi construída do zero para os fins do projeto, sendo uma parte significativa dos esforços para chegar nos resultados.
No total, foram construídas bases de dados de dez Captchas que estavam disponíveis publicamente no período de realização da pesquisa. Os Captchas foram revisados pela última vez no dia 14/09/2022, para verificar se ainda estavam ativos. Além disso, foram construídas duas bases de dados de Captchas desenvolvidos internamente para fins de teste.
Parte dos dados foram obtidos como um passo intermediário das simulações. A presente seção descreve como os robôs de coleta foram construídos, bem como a metodologia para obter os modelos iniciais. Na Seção 2.3.2, são apresentadas informações sobre os dados baixados para realizar as simulações.
Escolha dos Captchas analisados
Para selecionar os Captchas, foram adotados alguns critérios objetivos. Os critérios foram:
- O site acessado é de um serviço público (governo federal, tribunal etc).
- O Captcha contém letras (A a Z) e números (0 a 9) em uma imagem com extensão
jpegoupng. - O comprimento do Captcha é fixo, ou seja, dois Captchas da mesma origem devem ter sempre o mesmo comprimento.
A primeira restrição para escolha dos Captchas é de ordem principiológica: um serviço público não deveria restringir o acesso aos dados para robôs. Como já discutido na Seção 1.1, nesses casos, a existência do Captcha pode ser prejudicial para a sociedade.
As restrições 2 e 3 foram escolhidas com o objetivo de facilitar as simulações e comparações dos resultados. Em princípio, nada impede que os modelos desenvolvidos trabalhem com caracteres diferentes de [a-zA-Z0-9], desde que exista uma lista prévia de caracteres. Além disso, é possível realizar adaptações no tratamento das bases para lidar com diferentes comprimentos de Captchas.
A Tabela 2.1 mostra os Captchas trabalhados. Dos 10 exemplos trabalhados, 6 têm origem no judiciário, que são conhecidos por não disponibilizarem os dados de forma aberta. Vale notar que alguns dos Captchas da tabela são utilizados por vários tribunais. O Captcha TRT, por exemplo, existe em todos os Tribunais Regionais do Trabalho que compartilham a mesma versão do sistema do Processo Judicial eletrônico (PJe) do TRT3 (TRT da terceira região).
Captcha | Exemplo | Descrição |
|---|---|---|
| Tribunal Regional Federal 5 | |
| Tribunal de Justiça de Minas Gerais | |
| Tribunal Regional do Trabalho 3 | |
| Tribunal de Justiça da Bahia | |
| Junta Comercial de São Paulo | |
| Tribunal de Justiça de Pernambuco | |
| Tribunal de Justiça do Rio Grande do Sul | |
| Centro de Apoio ao Desenvolvimento da Saúde Pública | |
| Sistema Eletrônico de Informações - ME | |
| Receita Federal |










Além dos Captchas de sites, também foram consideradas imagens geradas artificialmente. O motivo de criar Captchas artificiais é a facilidade de rodar modelos e simulações, já que nos casos reais é necessário ter acesso à internet e construir bases de dados de cada Captcha.
Foram gerados dois tipos de Captchas artificiais. O primeiro, chamado MNIST-Captcha, é simplesmente uma adaptação da conhecida base MNIST para ficar no formato de um Captcha. A partir da escolha do comprimento e dos caracteres que fazem parte da imagem, o gerador simplesmente faz uma amostra aleatória da base do MNIST e compõe as imagens horizontalmente.
A Figura 2.13 mostra um exemplo do Captcha gerado a partir da base MNIST. No exemplo, o comprimento escolhido para o Captcha foi de 4 valores.

O problema do MNIST-Captcha é que a base de dados original é finita. Apesar de possuir por volta de 60 mil observações, o MNIST-Captcha pode gerar Captchas repetidos. Além disso, é necessário tomar cuidado com as bases de treino e teste, já que os elementos de teste não poderiam fazer parte de nenhuma observação de treino.
Um novo tipo de Captcha também foi gerado inteiramente por programação, chamado R-Captcha. O Captcha é gerado utilizando a ferramenta ImageMagick, com a possibilidade de customizar diversos parâmetros, como
- Quais caracteres usar na imagem
- O comprimento do Captcha
- Dimensões da imagem
- Probabilidade de rotação da imagem
- Probabilidade de adicionar um risco entre as letras
- Probabilidade de adicionar uma borda nas letras
- Probabilidade de adicionar uma caixa (retângulo) em torno das letras
- Probabilidade de adicionar um ruído branco no fundo da imagem
- Probabilidade de adicionar efeitos de tinta óleo e implosão
A Figura 2.14 mostra um exemplo de R-Captcha. O exemplo apresenta uma linha ligando as letras, comprimento 4, dígitos maiúsculos e minúsculos e distorções.

Por ser uma versão mais flexível e completa, optou-se por trabalhar principalmente com o R-Captcha nas simulações. O MNIST-Captcha foi implementado mas não foi utilizado nas simulações.
Construção dos dados
Para obter os dados da pesquisa, foram utilizadas técnicas de raspagem de dados (ZHAO, 2017). A raspagem de dados é uma área da ciência da computação responsável por criar rotinas que automatizam a coleta de dados provenientes da web. Trata-se de uma atividade muito comum em pesquisas aplicadas, especialmente as que envolvem análise de dados públicos que não estão disponíveis de forma aberta, como os dados do Judiciário.
Dentro do ciclo da ciência de dados, pode-se considerar que a raspagem de dados está inserida nas tarefas de coleta e arrumação de dados. É possível comparar a raspagem com uma consulta a um banco de dados remoto, ou mesmo à obtenção de informações através de uma Application Programming Interface (API).
Para raspar uma página da web, o fluxo descrito na Figura 2.15 é seguido. O exemplo da RFB foi utilizado para dar contexto aos passos.

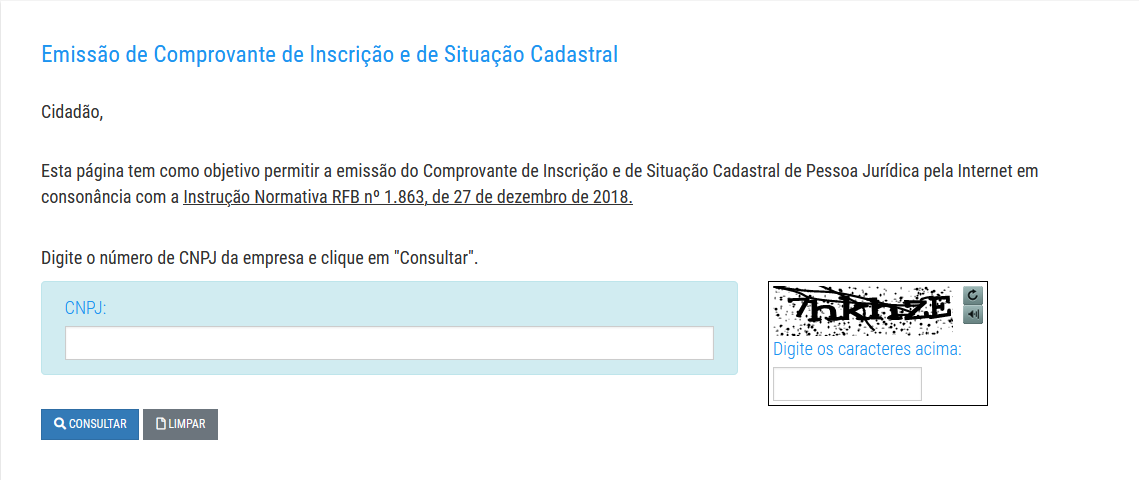
No caso da RFB, a etapa de identificação é realizada acessando-se a página inicial de busca de CNPJ, como mostrado na Figura 2.16. É possível notar que o desafio disponível é do tipo hCaptcha, que não é o Captcha de interesse da pesquisa. No entanto, ao clicar em “Captcha Sonoro”, é possível acessar o Captcha de interesse, como mostrado na Figura 2.17. O motivo pelo qual o Captcha de texto em imagem foi mantido após a implementação do hCaptcha não foi encontrado.

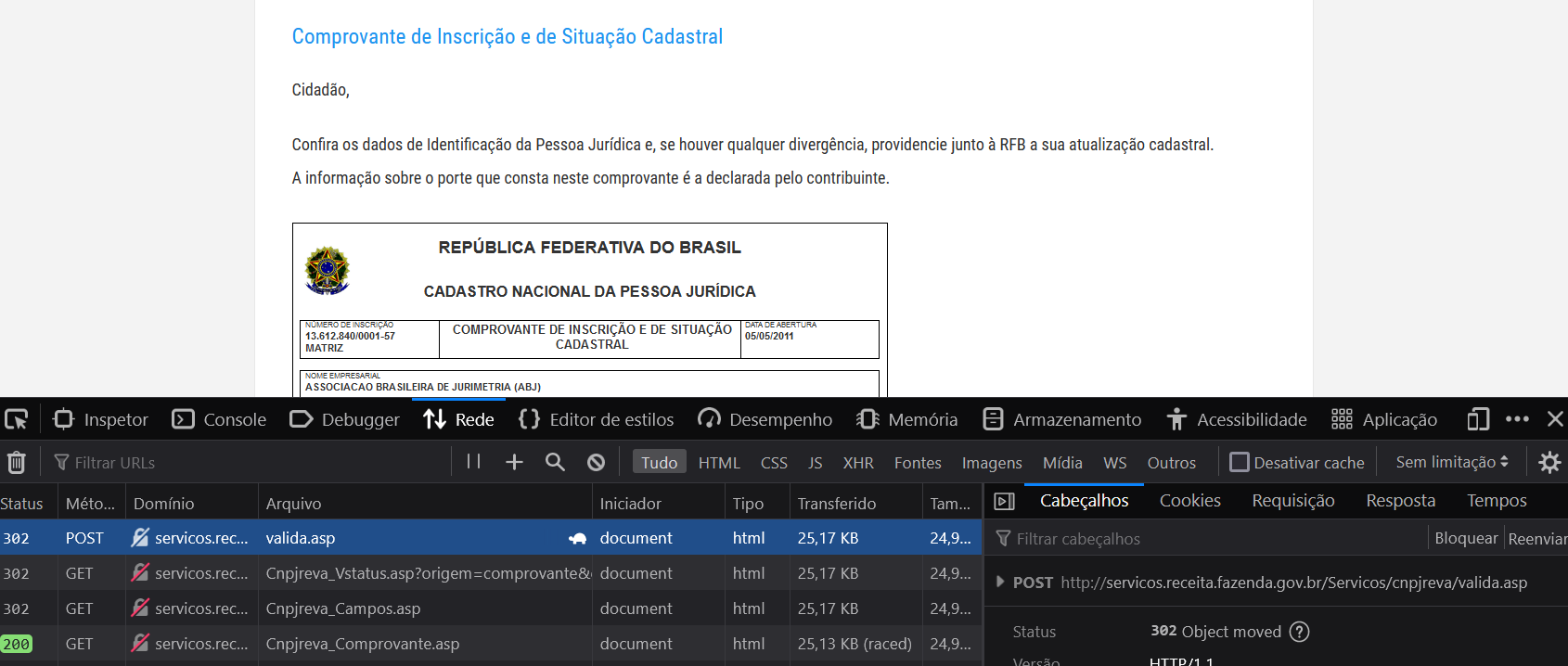
A segunda tarefa é a de navegar pelo site, registrando as requisições realizadas pelo navegador para realizar a consulta. Isso envolve abrir o inspetor de elementos do navegador, na aba Rede (ou Network, em inglês), anotando as requisições que são realizadas.
No exemplo, testou-se o CNPJ 13.612.840/0001-57, da ABJ. Ao preencher o CNPJ e o rótulo do Captcha, algumas requisições aparecem na aba “Rede”, como mostrado na Figura 2.18. A primeira requisição é do tipo POST5, responsável por enviar os dados de CNPJ e do rótulo da imagem para o servidor, que retorna com os dados da empresa.
Investigando a requisição POST, na aba “Requisição”, é possível observar os dados da consulta. Trata-se de um conjunto de parâmetros enviados na forma de lista, com as informações abaixo. Para replicar a requisição na linguagem de programação, estes são os dados enviados.
{
"origem": "comprovante",
"cnpj": "13.612.840/0001-57",
"txtTexto_captcha_serpro_gov_br": "7hkhze",
"search_type": "cnpj"
}As etapas de replicar e validar envolvem baixar e processar os dados obtidos no navegador, mas utilizando linguagem de programação. No caso do Captcha da RFB, essa tarefa envolve os passos abaixo.
- Acessar a página inicial de busca com Captcha sonoro, através de uma requisição GET.
- Baixar a imagem do Captcha com uma requisição GET, usando o link gerado ao clicar no botão de atualizar o Captcha.
- Obter o rótulo a partir da imagem do Captcha.
- Realizar a requisição POST com os dados do exemplo e o rótulo correto da imagem, baixando arquivo resultante em um HTML.
- Utilizar técnicas de raspagem de arquivos HTML para obter os dados de interesse (como, por exemplo, a razão social da empresa) e validar os resultados, verificando, por exemplo, se o resultado estava completo e disponível.
Todos os passos descritos acima devem ser realizados em uma sessão persistente. Isso significa que a biblioteca utilizada para realizar as requisições deve ser capaz de guardar os cookies entre a requisição GET do primeiro passo e a requisição POST do quarto passo, de forma que as requisições sejam interligadas.
O quinto passo da lista acima descreve a parte de parsear, que é a responsável pelo nome “raspagem” nesta área do conhecimento. O nome parsear aparece porque os arquivos baixados estão em um formato bruto, inadequado para realização de análises. Os dados precisam ser então extraídos – raspados – do arquivo HTML, utilizando ferramentas como a libxml2 (WICKHAM; HESTER; OOMS, 2021) para acessar pedaços do documento, como o XPath (WICKHAM, 2022a) e posteriormente aplicar técnicas de manipulação de textos, como expressões regulares (WICKHAM, 2022b).
A iteração encerra o fluxo da raspagem de dados. Nessa etapa, as operações de replicar, parsear e validar o resultado são repetidas, com o fim de baixar dados para compor uma base maior. No exemplo da RFB, isso significaria montar uma base de dados a partir de uma lista de CNPJs.
No contexto dos Captchas, o interesse principal está nos passos de replicar e validar. Primeiro, a imagem é baixada e o rótulo é anotado – replicar. Em seguida, o rótulo é testado pelo oráculo – validar.
O oráculo envolve a possibilidade de checar, de forma automática, se uma predição do rótulo de uma imagem está correta. O Captcha é obrigado a mencionar se uma predição está correta: se a predição foi correta, a página de interesse é acessada; se a predição está incorreta, o site envia uma mensagem de erro.
De forma geral, as etapas de replicar e validar em todos os sites de interesse envolveram os passos a seguir.
- Acessar a página do site de interesse.
- Preencher o formulário de pesquisa com a informação a ser consultada. Por exemplo, no site da RFB, a informação é o CNPJ da empresa a ser consultada. Em um site de tribunal, a informação é um número identificador de processo.
- Baixar a imagem do Captcha da busca.
- Obter o rótulo da imagem, aplicando um modelo na imagem baixada ou anotando manualmente.
- Submeter a consulta no site, informando o rótulo.
- Verificar o resultado. Se acessou a página desejada, o rótulo está correto. Caso contrário, o rótulo está incorreto.
O procedimento descrito pode ser reproduzido indefinidamente. Isso significa que é possível criar uma base de dados virtualmente infinita de imagens rotuladas, com a informação adicional do rótulo estar correto ou incorreto. Isso foi feito para gerar os dados utilizados na simulação.
Uma oportunidade que o oráculo pode oferecer é a possibilidade de testar mais de uma predição. Sites com essa característica permitem que a pessoa ou robô teste mais de uma predição caso a tentativa anterior tenha resultado em fracasso. Como é possível observar na Tabela 2.1, dos 10 Captchas trabalhados, 7 permitem a realização de múltiplos chutes.
Neste momento, cabe uma nota sobre oráculos e força bruta. O poder de testar vários rótulos para o mesmo Captcha implica na possibilidade teórica de resolver um Captcha por força bruta. Bastaria testar todos os rótulos possíveis para acessar a página de interesse. Na prática, no entanto, essa estratégia não funciona, já que a quantidade de rótulos possíveis é muito grande para testar no site, seja por demorar muito tempo ou pelo site forçar a troca do desafio após a passagem de determinado tempo ou quantidade de tentativas.
Voltando ao ciclo da raspagem, ao longo do procedimento de baixar imagens de Captchas e aplicar o oráculo, pelo menos duas operações devem ser implementadas: acesso e teste. A operação de acesso é responsável por preencher o formulário de busca e baixar o Captcha (passos 1, 2 e 3 da lista acima). A operação de teste é responsável por submeter um rótulo do Captcha e verificar se o rótulo está correto ou incorreto (passos 5 e 6 da lista acima). O passo 4 pode ser realizado de forma unificada, pois não depende de interação com o site específico. Em alguns casos, as funções de acesso e teste precisam compartilhar parâmetros que contêm a sessão do usuário, para garantir que o teste envolva o mesmo Captcha da etapa de acesso.
Os Captchas foram anotados manualmente com um procedimento que foi chamado de semi-automático, definido a seguir. No pacote {captchaDownload} (ver Apêndice A.1), foram desenvolvidas ferramentas para baixar e organizar cada Captcha, utilizando o oráculo para garantir que as imagens eram corretamente anotadas.
Cada Captcha teve as primeiras 100 observações anotadas manualmente. Isso foi feito a partir do próprio RStudio, utilizando a ferramenta de anotação manual do pacote {captcha}.
A partir das anotações iniciais, um modelo inicial foi ajustado. Esse passo também foi feito com o pacote {captcha}, que possui uma função de ajuste de modelos que usa redes neurais convolucionais, definidas da mesma forma que nas seções anteriores.
O modelo, então, foi utilizado como uma ferramenta para otimizar a anotação manual, funcionando da seguinte forma. Primeiro, o modelo tenta realizar a predição automaticamente e o oráculo informa se a predição está correta ou não. Se estiver incorreto e o site aceitar vários chutes, o modelo tenta novamente, mas com uma segunda alternativa de predição. Caso o site não aceite vários chutes ou o modelo não consiga acertar o Captcha em \(T\) tentativas (arbitrado como dez), o Captcha é anotado manualmente.
Com o procedimento destacado acima, é criada uma nova base de dados, que por sua vez é utilizada para ajustar um novo modelo. O modelo, atualizado, é utilizado para classificar novos Captchas, e assim por diante, até que o modelo ajustado alcance uma acurácia razoável, que foi arbitrada em 80%. Com isso o procedimento de anotação é finalizado.
O único problema do procedimento de anotação descrito diz respeito aos Captchas que não aceitam várias tentativas. Nesses casos, não é possível verificar com certeza que um caso anotado manualmente (após a tentativa do modelo) foi anotado corretamente, já que a anotação manual seria a segunda tentativa. No entanto, esse problema aparece somente em três Captchas (cadesp, jucesp e trf5). A anotação manual dos 100 primeiros Captchas, no entanto, mostrou que pelo menos 95% dos Captchas foram anotados corretamente quando anotados manualmente. A proporção máxima de 5% de erro é negligenciável considerando que a maior parte das bases de dados foi construída com verificação do oráculo.
Em alguns casos, os rótulos dos Captchas podem ser obtidos sem intervenção humana, utilizando técnicas de raspagem de dados ou processamento de sinais. Um exemplo é o Captcha do SEI, que mostra informações suficientes para resolver o Captcha na própria URL que gera a imagem. Outro exemplo é o TJMG, que libera, além da imagem, um áudio contendo o mesmo rótulo da imagem, sem a adição de ruídos. Como o áudio não tem ruídos, basta ler o áudio, separar os áudios de cada caractere e calcular uma estatística simples (como a soma dos valores absolutos das amplitudes). Essa estatística é utilizada para associar um pedaço de áudio a um caractere.
A Tabela 2.2 caracteriza os Captchas anotados. Todos os Captchas possuem comprimento entre 4 e 6 dígitos e, com exceção do SEI, não são sensíveis a maiúsculas e minúsculas.
Captcha | Vários chutes | Caracteres | Comprimento | Colorido | # Rótulos anotados |
|---|---|---|---|---|---|
Não | 0-9 | 6 | não | 1000 | |
Sim | 0-9 | 5 | sim | 1000 | |
Sim | a-z0-9 | 6 | não | 1500 | |
Sim | a-z | 5 | sim | 3000 | |
Não | a-z0-9 | 5 | não | 4000 | |
Sim | a-z0-9 | 5 | não | 4000 | |
Sim | 0-9 | 4 | sim | 2000 | |
Não | a-z | 4 | sim | 3000 | |
Sim | a-zA-Z0-9 | 4 | sim | 10000 | |
Sim | a-z0-9 | 6 | não | 4000 |
As bases de dados com imagens anotadas foram disponibilizadas na aba de lançamentos (releases) do repositório principal do projeto de pesquisa. As bases com imagens e modelos ajustados estão disponíveis para quem tiver interesse em fazer novas pesquisas e utilizar os resultados em suas aplicações, sem restrições de uso.
Simulações
Para verificar o poder do uso do oráculo para o aprendizado do modelo, uma série de simulações foram desenvolvidas. As simulações foram organizadas em três passos: modelo inicial, dados e modelo final. Os passos foram descritos em maior detalhe a seguir.
Primeiro passo: modelo inicial
A simulação do modelo inicial teve como objetivo obter modelos preditivos de Captchas com acurácias distintas. O modelo inicial seria usado, então, para baixar dados diretamente do site usando o oráculo e, por fim, ajustar um modelo final com os novos dados provenientes do oráculo.
Os modelos iniciais para cada Captcha foram construídos em dois passos. O primeiro foi montar a base de dados completa, suficiente para ajustar um modelo com alta acurácia, que arbitrados em 80%, como descrito anteriormente. Depois, montou-se 10 amostras de dados com subconjuntos das bases completas, cada uma contendo 10%, 20%, e assim por diante, até a base completa. Por exemplo: no Captcha da Jucesp, construiu-se um modelo com acurácia maior que 80% com 4000 Captchas. A partir disso, foi feita uma partição dos dados com 400 imagens (10% do total), 800 imagens (20% do total) e assim por diante, até o modelo com 4000 Captchas. A utilização de diferentes tamanhos de base de dados foi realizada para obter modelos com diferentes acurácias.
Para cada tamanho de amostra \(S\), aplicou-se uma bateria de 27 modelos. Isso foi feito porque para diferentes quantidades de amostra, a configuração dos hiperparâmetros que resulta no melhor modelo pode ser diferente. Os modelos seguiram uma grade de hiperparâmetros considerando três informações:
- A quantidade de unidades computacionais na primeira camada densa após as camadas convolucionais, com os valores considerados: 100, 200 e 300.
- O valor do dropout aplicado às camadas densas, com os valores considerados: 10%, 30% e 50%.
- O fator de decaimento na taxa de aprendizado a cada época, com os valores considerados: 1%, 2% e 3%.
Os diferentes valores de hiperparâmetros foram escolhidos com base em vários testes empíricos realizados antes da simulação. Nesses testes, foram considerados Captchas com diferentes complexidades e bases de dados com diferentes tamanhos. Os números escolhidos visaram proporcionar uma boa cobertura de modelos que poderiam ser os melhores, ao mesmo tempo que seria uma grade simples o suficiente para permitir a realização da simulação em tempo hábil.
Combinando os três valores dos três hiperparâmetros, tem-se um total de \(27=3^3\) hiperparâmetros. Com isso, foi possível identificar, para cada tamanho de amostra \(S\), o classificador com a melhor acurácia dentre os modelos ajustados.
Todos os modelos foram ajustados utilizando-se um computador com um processador Intel Core i7 10700KF, 3.80GHz (5.10GHz Turbo), 64GB de RAM e uma placa GeForce RTX 3080 Eagle OC 10G. Os códigos utilizaram a linguagem de programação R na versão 4.1.2 e o pacote {torch} na versão 0.7.1.
No final do primeiro passo, portanto, considera-se apenas o melhor modelo para cada tamanho de amostra, dentre os 27 ajustados. É claro que os modelos encontrados por essa técnica não são, necessariamente, os melhores modelos possíveis. No entanto, como a técnica é a mesma para todos os Captchas, é possível fazer comparações através de uma metodologia mais transparente.
Uma discussão interessante que aparece nesse contexto é a escolha de pacotes da linguagem de programação R no lugar de Python para o ajuste dos modelos. Para a construção deste trabalho, utilizou-se o R em todos os passos, seja na construção do pacote {captcha}, o ajuste dos modelos e raspadores de dados. No entanto, o Python é uma linguagem reconhecidamente popular para tarefas de aprendizado de máquina e raspagem de dados. Neste trabalho, optou-se utilizar o R por dois motivos: i) a experiência do autor nesta linguagem, que é muito maior em R do que em Python e ii) a possibilidade de utilizar o pacote {torch}, que foi desenvolvido por um ex-aluno do IME-USP, Daniel Falbel. A utilização do {torch} não só facilitou a construção da solução como também pode ser pensada como um incentivo para que outros pesquisadores da estatística utilizem esse pacote computacional.
Uma possível desvantagem ao utilizar o R é que isso poderia trazer dificuldades na velocidade da simulação. No entanto, isso não acontece na prática. No momento do ajuste dos modelos, existia uma diferença de performance do {torch} com relação ao PyTorch, do Python. No entanto, essa diferença é negligenciável ao considerar o tempo total de ajuste dos modelos, incluindo a parte de acesso à internet. O que torna o download dos dados lento não é a linguagem utilizada, e sim a própria conexão com a internet e potenciais bloqueios do site de origem. Por isso, os tempos para executar as simulações usando R ou Python seriam similares.
Segundo passo: dados
O segundo passo teve como objetivo construir as bases de dados utilizando o oráculo. Primeiro, foi necessário decidir quais modelos, dentre os 10 ajustados para cada Captcha, seriam utilizados para construir novas bases. Não faria sentido, por exemplo, considerar um modelo com acurácia de 0%, já que ele não produziria nenhuma observação comparado com um modelo que chuta aleatoriamente. Também não faria sentido considerar um classificador com acurácia de 100%, já que nesse caso não há o que testar com a técnica do oráculo.
Decidiu-se que seria necessário considerar somente os modelos que resultaram em acurácias maiores de 5% e menores de 50%. O valor máximo foi decidido após realizar alguns testes empíricos e verificar, informalmente, que a técnica do oráculo realmente resultava em ganhos expressivos, mesmo com modelos de baixa acurácia. Concluiu-se então que não seria necessário testar a eficácia da técnica para classificadores com alta acurácia. Já o valor mínimo foi decidido de forma arbitrária, retirando-se os classificadores com acurácia muito baixa.
A segunda decisão a ser tomada para construção dos dados foi a quantidade de imagens que seria baixada para cada Captcha. Como são Captchas de diferentes dificuldades, a quantidade de dados seria diferente para cada tipo. Optou-se por baixar a quantidade de dados de forma a montar uma base de treino que contém a quantidade de observações necessária para obter o melhor modelo daquele Captcha. Por exemplo, no TJRS, um modelo com acurácia próxima de 100% foi identificado com 2000 observações. O melhor modelo com 300 imagens (240 para treino, 60 para teste) resultou em uma acurácia de 35%. Foram, então, baixadas 1760 observações para compor o total de 2000 na base de treino. As imagens de teste do modelo inicial poderiam até ser utilizadas, mas optamos por descartar para garantir que o modelo não ficasse sobreajustado para a primeira base.
O motivo de baixar a mesma quantidade de observações que o melhor modelo inicial foi feita por três motivos. O primeiro é que existem evidências de que é possível construir um bom modelo com essa quantidade de imagens, ainda que em um caso as informações são completas e, no outro, incompletas. O segundo é que isso permite a comparação do resultado do modelo completamente anotado contra o modelo que é parcialmente anotado e com anotações incompletas provenientes do oráculo. A terceira é que essa estratégia proporciona bases de dados com diferentes proporções de dados parcialmente anotados, o que pode trazer resultados empíricos de interesse, como avaliar se muitos casos parcialmente rotulados podem atrapalhar o ajuste do modelo.
A terceira e última decisão tomada para baixar os dados foi a quantidade de chutes que o modelo poderia fazer, nos casos em que isso é permitido pelo site. Optou-se, de forma arbitrária, por três valores: 1, que é equivalente a um site que não permite múltiplos chutes, 5 chutes e 10 chutes.
Portanto, o procedimento de coleta dos dados foi feito, para cada Captcha, da seguinte forma:
- Listou-se todos os melhores modelos ajustados para cada tamanho de amostra.
- Filtrou-se os modelos para os que apresentaram acurácia de 5% até 50%.
- Definiu-se o tamanho da base a ser obtida, com base no tamanho da base de treino utilizada no modelo e a quantidade total que se objetivou obter.
- Para cada quantidade de tentativas disponível (1, 5 e 10), baixou-se as imagens, anotando com o valor “1” se o rótulo de alguma das tentativas estivesse correto e com o valor “0” caso contrário.
- Nos casos com erros, armazenou-se um arquivo de log para cada Captcha com o histórico de tentativas incorretas, que é a informação mais importante a ser passada para o modelo final.
No final, obteve-se bases de dados de treino para todos os Captchas analisados, com quantidades de imagens que variam de acordo com os parâmetros definidos anteriormente e pela quantidade de tentativas. A quantidade total de bases de dados geradas foi 65.
Além das bases de treino, foi construída uma base de teste para cada Captcha. O tamanho das bases de teste foi arbitrado em 1000 imagens para cada Captcha. As bases de teste foram construídas completamente do zero, sem utilizar informações de bases anteriores. Para construir as bases, utilizou-se a mesma técnica semiautomática definida anteriormente, usando o melhor modelo disponível para classificar a maioria das imagens e classificando manualmente em caso de falha. Em alguns casos, como TJMG e TJRS, a anotação humana quase não foi necessária, pois os melhores classificadores obtidos apresentaram acurácia próxima de 100%.
Terceiro passo: modelo final
O modelo final foi ajustado para cada uma das 65 bases de treino disponíveis após a realização dos passos 1 e 2. Nesse caso, utilizou-se o modelo proposto na Seção 2.2. Caso a imagem tenha sido corretamente anotada, a função de perda é calculada normalmente. Caso ela tenha sido anotada incorretamente, considera-se a probabilidade de não observar nenhum dos chutes.
Além de modificar a forma de calcular a função de perda do modelo, foi necessário realizar uma nova busca de hiperparâmetros. Optou-se por utilizar os mesmos hiperparâmetros dos modelos iniciais para manter a consistência. O único detalhe nesse ponto é que, como os parâmetros de partida são os do modelo inicial, optou-se por não modificar a quantidade de unidades na camada densa, variando somente os valores de dropout e de decaimento na taxa de aprendizado. Portanto, ajustou-se 9 e não 27 modelos para cada base de dados.
No final, assim como no primeiro passo, os classificadores com melhor acurácia foram selecionados para cada modelo. Obteve-se, então, uma lista de 65 modelos ajustados para comparar com os modelos iniciais e estimar a efetividade do oráculo. As comparações foram feitas através de gráficos de barras, explorando o efeito do uso do oráculo para diferentes Captchas, diferentes modelos iniciais e diferentes quantidades de chutes, além de um gráfico de dispersão para relacionar as acurácias iniciais e finais.
Além do terceiro passo, outros experimentos foram realizados para verificar se, ao aplicar a técnica do oráculo iterativamente, os resultados continuariam melhorando. Ou seja, é possível considerar os modelos obtidos no passo 3 como os modelos iniciais do passo 1, aplicar novamente o passo 2 (baixar dados) e o passo 3 (rodar modelo com os novos dados). Isso foi feito para apenas um conjunto selecionado de Captchas para verificar essa possibilidade, não fazendo parte das simulações principais do estudo.
As bases de dados das simulações também foram disponibilizadas na aba de lançamentos (releases) do repositório principal do projeto de pesquisa. As bases podem ser utilizadas para aumentar as bases de treino e para testar outras arquiteturas de redes neurais ao tema dos Captchas com uso de aprendizado fracamente supervisionado.
existem exemplos de Captchas baseados em imagens que não são limitados a letras e números para constituir o rótulo (KAUR; BEHAL, 2014). Como esses casos não aparecem nas aplicações práticas de interesse, estão fora do escopo do trabalho.↩︎
A matriz foi multiplicada por 1000 para não extrapolar as margens do documento.↩︎
Mais sobre o (py)torch: https://pytorch.org. Último acesso em 22 de novembro de 2022.↩︎
Mais detalhes em https://www.tensorflow.org. Último acesso em 22 de novembro de 2022.↩︎
Existem dois tipos principais de requisição HTTP. A requisição GET serve para capturar uma página da internet, enquanto a requisição POST serve para enviar dados para o servidor como, um login e uma senha. A lista completa de requisições está disponível na documentação da Internet Engineering Task Force (IETF).↩︎