3 Resultados
I’m not a robot, I’m a human. But I’m pretty sure the robot is better at this than I am.
– ChatGPT
Neste capítulo, discute-se os resultados empíricos do método WAWL e descreve-se o pacote computacional desenvolvido para trabalhar com Captchas. A Seção 3.1 mostra os resultados empíricos e a Seção 3.2 detalha o pacote {captcha}. No final, a Seção 3.3 apresenta uma discussão dos resultados obtidos.
Resultados empíricos
Os resultados foram obtidos a partir das simulações com diversos Captchas. Foram realizadas 65 simulações no total, variando o tipo de Captcha, a acurácia do modelo inicial e a quantidade de tentativas no oráculo, como descrito na Seção 2.4.
A base de dados com os resultados das simulações está disponível publicamente no repositório da tese1. A base contém informações do Captcha ajustado (captcha), da quantidade de observações do modelo inicial (n), da quantidade de tentativas do oráculo (ntry), da etapa de simulação (fase, inicial ou WAWL), do caminho do modelo ajustado (model) e da acurácia obtida (acc).
Os resultados gerais mostram um ganho de 333% na acurácia após a aplicação do método WAWL. Ou seja, em média, a acurácia do modelo no terceiro passo da simulação (ver a Seção 2.4.3) foi de mais de três vezes a acurácia do modelo inicial. Em termos absolutos (diferença entre as acurácias), o ganho foi de 33%, ou seja, após o terceiro passo, os modelos ganharam, em média, 33% de acurácia.
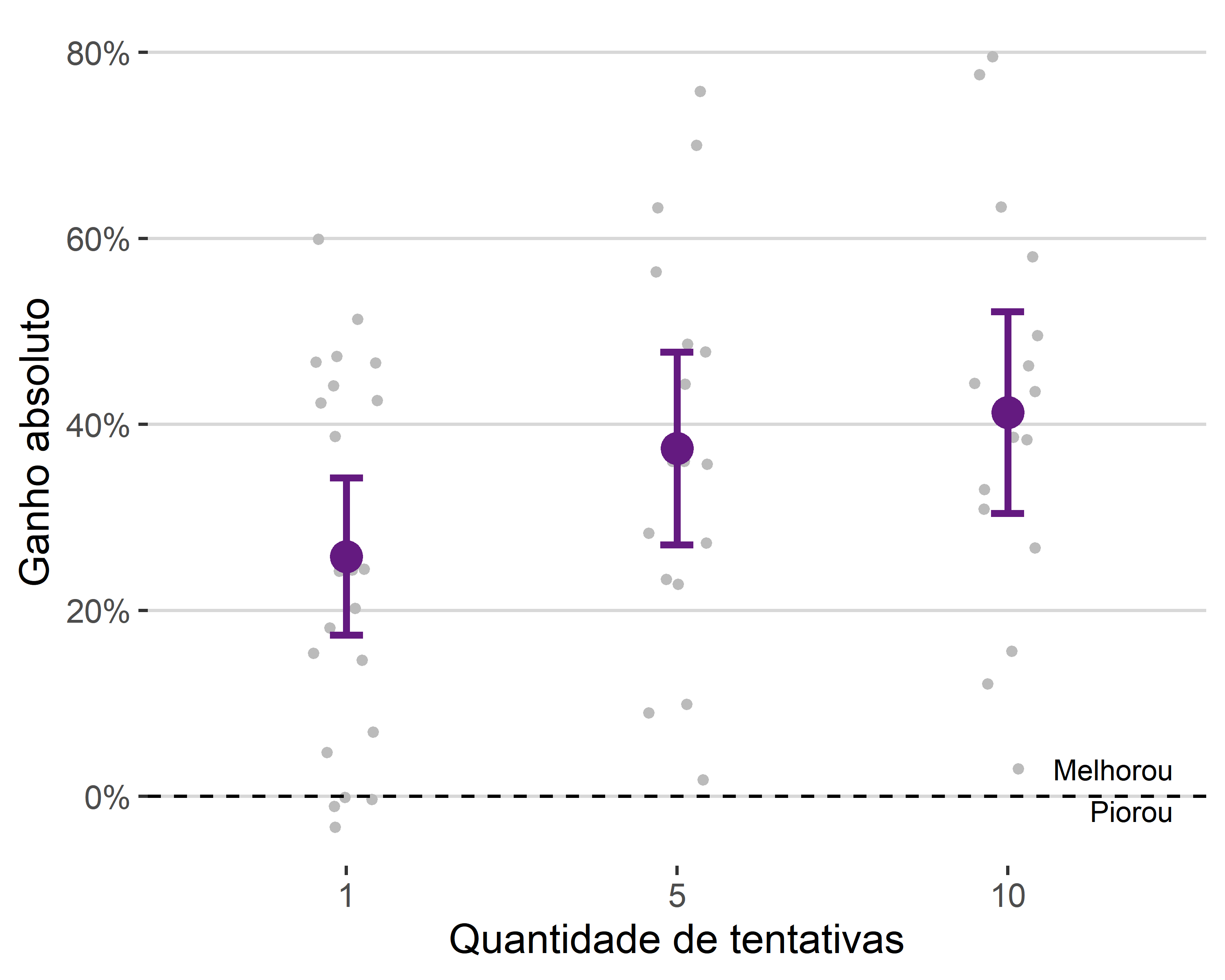
As Figuras 3.1 e 3.2 mostram os ganhos relativos e absolutos, separando os resultados gerais por quantidade de tentativas. Cada ponto é o resultado de uma simulação e o ponto em destaque é o valor médio, acompanhado de intervalo \(m \mp 2*s/\sqrt(n)\), com \(m\) sendo a média, \(s\) o desvio padrão e \(n\) a quantidade de dados. A linha pontilhada indica se a acurácia aumentou ou diminuiu após a aplicação da técnica.
Na Figura 3.1, é possível notar que os ganhos em acurácia apresentam alta variabilidade, mas que apresentam uma tendência positiva com relação ao número de tentativas. O ganho entre aplicar 5 e 10 tentativas é menos expressivo do que o ganho entre aplicar 1 e 5 tentativas, indicando que a oportunidade oferecida por sites que aceitam vários chutes é relevante, mas não há necessidade de realizar tantos chutes para aproveitar essa oportunidade. Uma possível explicação para isso é que o modelo ficaria indeciso entre poucas opções.
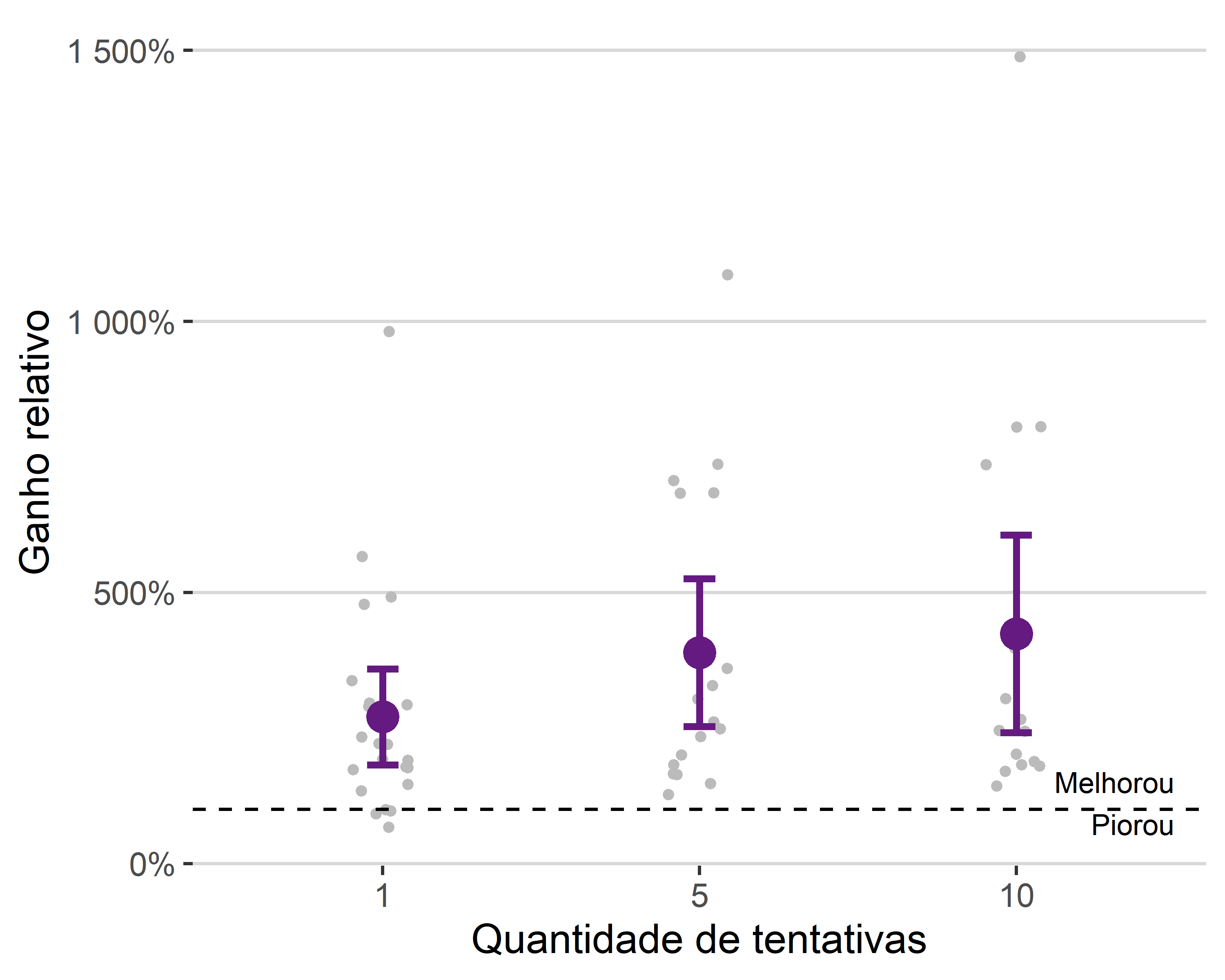
A Figura 3.2, com as os ganhos absolutos, mostra a mesma informação, mas em valores com interpretação mais direta. O ganho médio absoluto em sites que permitem mais de um chute ficou em torno de 40%, enquanto o ganho com apenas um chute ficou um pouco acima de 25%. Também é possível notar que a técnica é efetiva de forma consistente, já que resultou em pioras nas acurácias em poucos casos, sendo todos eles no cenário com apenas um chute.
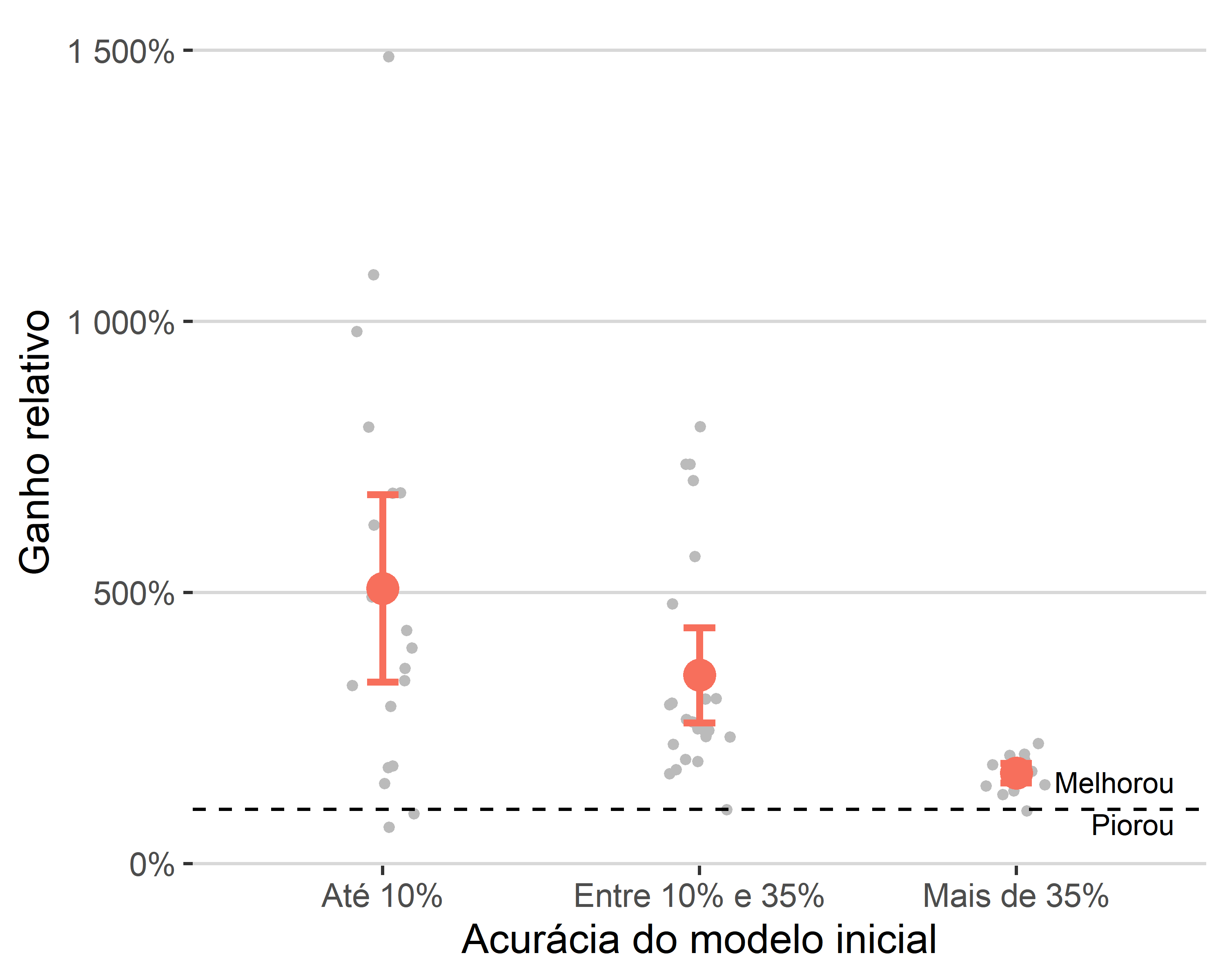
As Figuras 3.3 e 3.4 apresentam os resultados gerais separando por acurácia inicial do modelo. A estrutura do gráfico é similar às visualizações anteriores, que separaram os resultados por quantidade de tentativas. As categorias escolhidas foram: até 10%, mais de 10% até 35% e mais de 35% de acurácia no modelo inicial. A escolha dos intervalos se deram pela quantidade de observações em cada categoria.
A Figura 3.3 mostra os ganhos relativos. É possível notar uma tendência de queda no ganho de acurácia com uso do oráculo conforme aumenta a acurácia do modelo inicial. Esse resultado é esperado, pois, como a acurácia é um número entre zero e um, um modelo que já possui alta acurácia não tem a possibilidade de aumentar muito de forma relativa.
A Figura 3.4 mostra os ganhos absolutos. O gráfico apresenta o mesmo problema que o anterior, já que o ganho máximo depende da acurácia inicial do modelo. Ainda assim, é possível notar que, em termos absolutos, modelos com acurácia inicial entre 10% e 35% apresentaram um ganho maior que modelos com acurácia inicial de até 10%.

Para lidar com o fato de a acurácia ser um número limitado, fizemos o mesmo gráficos de antes, mas ajustado pelo máximo possível que a técnica do oráculo poderia proporcionar. O ganho absoluto ajustado de uma simulação é dado por
\[ \text{ganho} = \frac{\text{wawl } - \text{ inicial}}{1\; - \text{ inicial}}. \]
A Figura 3.5 mostra os ganhos ajustados. Pelo gráfico, é possível notar que existe um ganho expressivo do WAWL para modelos iniciais com mais de 10% de acurácia com relação a modelos iniciais com até 10% de acurácia. Ou seja, quando o modelo inicial é fraco, o ganho ao usar o método é um pouco menor. É importante notar, no entanto, que as simulações consideram a aplicação do WAWL apenas uma vez – é possível baixar mais dados e atualizar o modelo indefinidamente, como mostrado mais adiante na Figura 3.7. O menor efeito do método para modelos iniciais fracos não significa, portanto, que a técnica não funciona para modelos iniciais fracos; pelo contrário: ela ajuda o modelo a sair do estado inicial e o leva para um estado com acurácia maior, de onde seria possível aplicar a técnica novamente para obter resultados mais expressivos.

Na Figura 3.6, são apresentados os resultados separados por Captcha. Cada linha é uma combinação de Captcha, quantidade de tentativas e acurácia modelo inicial, classificados nas três categorias mostradas anteriormente. As linhas pontilhadas indicam modelos ajustados com mais de uma tentativa, enquanto as linhas contínuas mostram modelos ajustados com apenas uma tentativa. A primeira extremidade de cada linha, do lado esquerdo, indica a acurácia do modelo inicial e a segunda extremidade, do lado direito, a acurácia do modelo usando o método WAWL.
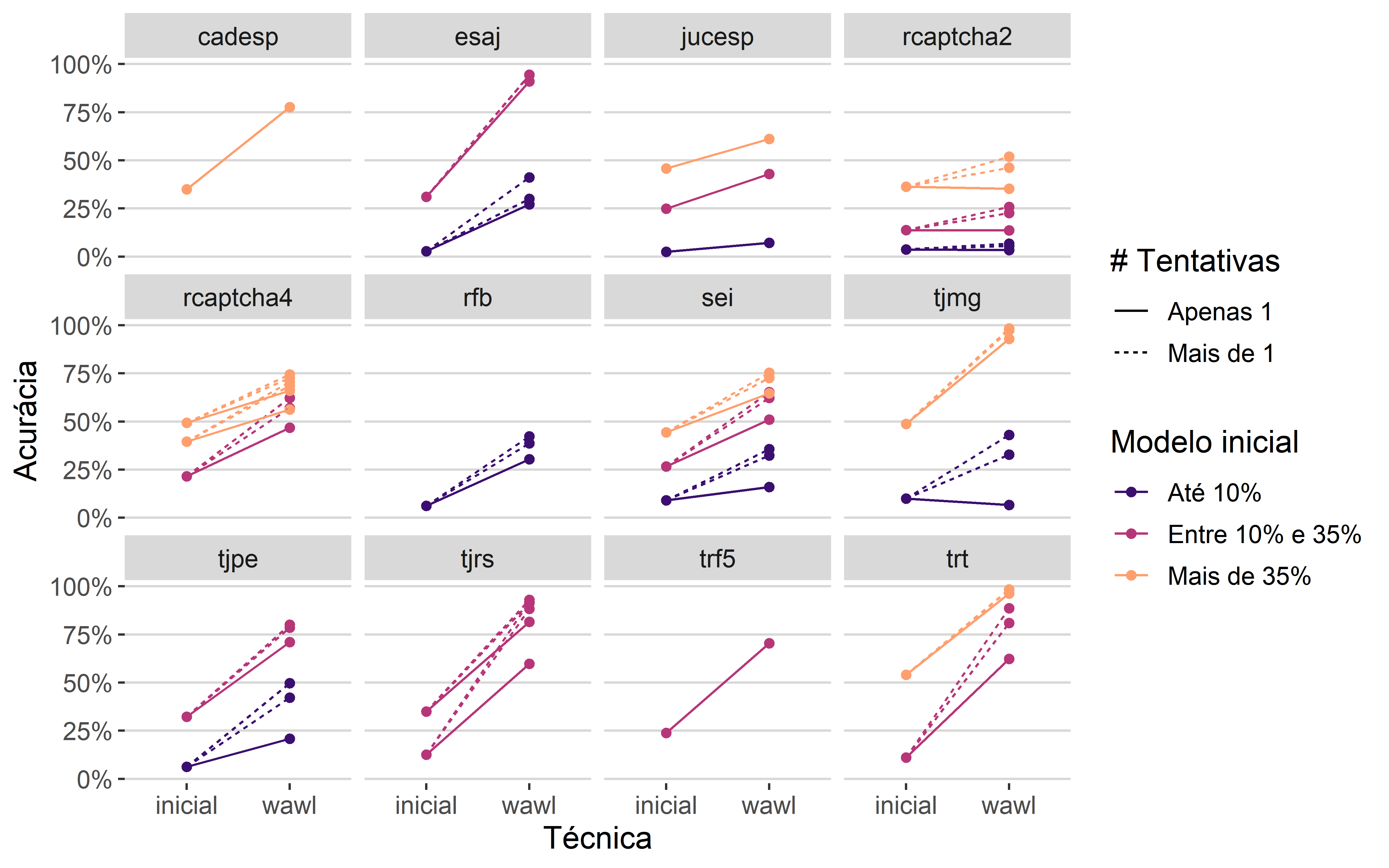
Pelo gráfico, é possível identificar duas informações relevantes. Como já verificado anteriormente, os modelos ajustados com mais de uma tentativa apresentam maiores ganhos do que os modelos ajustados com apenas uma tentativa. Verifica-se também que modelos com acurácia inicial de até 10% só apresentam ganhos menores que os modelos com acurácia inicial maior que 10% nos casos com apenas um chute. Ou seja, existe interação entre a quantidade de chutes e a acurácia do modelo inicial ao avaliar o impacto nos ganhos empíricos do método WAWL.
Pelos resultados das simulações, é possível concluir que o método WAWL foi bem-sucedido. Primeiro, o método apresenta resultados expressivos e de forma consistente, mesmo sem realizar novas anotações manuais. Além disso, a técnica consegue aproveitar oportunidade oferecida pelos sites de obter o feedback oráculo múltiplas vezes na mesma imagem. Finalmente, o método apresenta, em média, resultados positivos mesmo para modelos iniciais muito fracos (com acurácia de até 10%), indicando que sua aplicação é possível para qualquer modelo inicial, o que é bastante factível de atingir com bases pequenas ou com modelos generalistas para resolver Captchas.
Um possível problema em aplicar o WAWL é que a técnica poderia introduzir viés de seleção no modelo, impedindo-o de ser aprimorado indefinidamente. Mesmo que os resultados teóricos deem uma boa base para concluir que isso não seja verdade, foi feito um experimento adicional, com apenas um dos Captchas, para verificar se a aplicação da técnica múltiplas vezes apresenta bons resultados.
O Captcha escolhido para a simulação foi o trf5, por ser um Captcha que não aceita múltiplos chutes, em uma tentativa de obter um pior caso. Para esse Captcha, o melhor modelo obtido com a técnica do oráculo foi considerado como modelo inicial, sendo usado para baixar novos dados do site do Tribunal. Os novos dados foram adicionados à base de treino, ajustando-se um novo modelo.
A Figura 3.7 mostra os resultados da aplicação iterativa. A utilização da técnica não só funcionou como levou o modelo a uma acurácia de 100%.
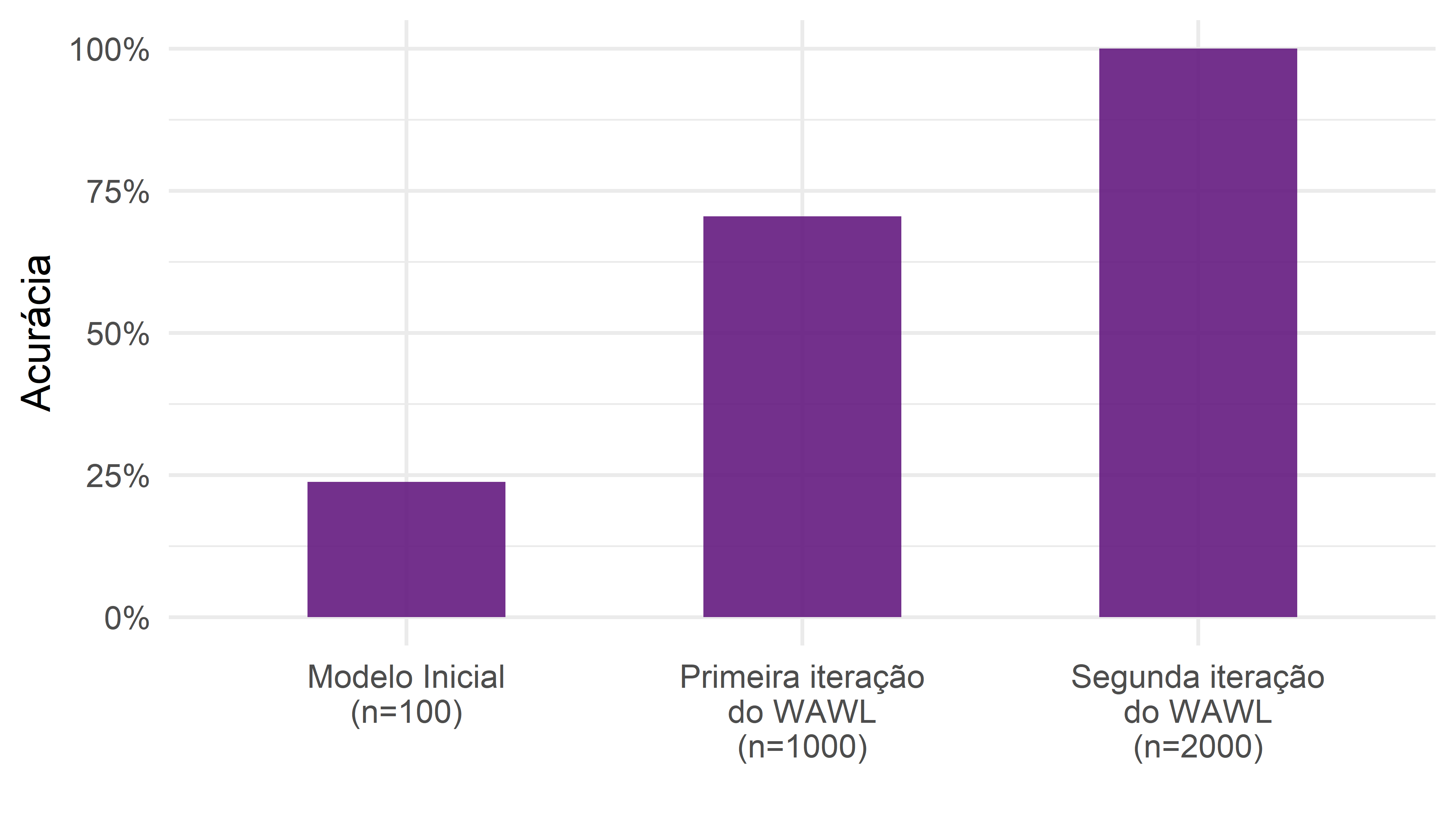
O resultado sugere que o método WAWL pode ser aplicado iterativamente para aprimorar o aprendizado do modelo. Ele sugere, ainda, que uma técnica de aprendizado ativo com feedback automático do oráculo pode dar bons resultados, já que a forma de obter os dados não introduz viés de seleção no ajuste do modelo.
Nesse sentido, foi aplicado também um experimento de uma ferramenta de online learning. A ferramenta funciona da seguinte forma: ao invés de aplicar os passos do WAWL (baixar dados e ajustar novo modelo) de forma separada, obtêm-se amostras do oráculo em cada passo do ajuste do modelo. Ou seja, as técnicas de raspagem de dados entram de forma direta no ciclo de aprendizagem.
O experimento foi feito utilizando o Captcha do TJRS com os passos a seguir. O modelo, função de perda e base de testes são exatamente os mesmos utilizados na simulação completa. No entanto, os dados baixados pelo oráculo não são considerados. Ao invés disso, o minibatch é construído baixando dados diretamente da internet e aplicando o modelo inicial.
Para permitir que o modelo aproveite casos baixados em minibatches anteriores, o modelo considera uma probabilidade de baixar novos casos, arbitrada em 80%. Assim, para cada elemento do minibatch, com 80% de probabilidade, a observação é baixada da internet, e com 20% de probabilidade, a observação é uma amostra dos casos anteriores já baixados. Como forma de obter um pior caso, o modelo não considera nem mesmo os dados utilizados para construir o modelo inicial.
O valor do minibatch foi arbitrado em 40 observações, como na etapa de simulação. O número de minibatches de uma época é indefinido, porque não existe um número máximo de amostras. A época foi arbitrada como sendo a passagem de 2 minibatches, para permitir a atualização do modelo inicial.
A atualização do modelo inicial é realizada ao fim de cada época. Se ao fim do ciclo (ou seja, ao fim de 2 minibatches) o modelo ajustado possui uma acurácia melhor na base de teste do que o modelo inicial, o modelo é atualizado para a versão atual. Se não, o modelo inicial é mantido. Dessa forma, os minibatches construídos ficam cada vez mais informativos, uma vez que vão acertar mais o rótulo da imagem.
O experimento considerou um modelo inicial com apenas 11% de acurácia. O TJRS foi escolhido como exemplo porque o site é relativamente estável, além de permitir múltiplos chutes. O número de chutes permitidos ao modelo foi arbitrado em 5. Na parte dos hiperparâmetros, como a época é curta (apenas 80 observações por época), o decaimento na taxa de aprendizado considerado foi 0.999. Os valores de dropout e quantidade de unidades na camada densa foram as mesmas do modelo inicial.
O resultado do experimento foi promissor. A partir do modelo inicial 11% de acurácia, após 100 épocas, o modelo baixou 6391 imagens e chegou em uma acurácia de 87% na base de teste. A Figura 3.8 mostra a evolução da acurácia do modelo ao longo das épocas. Como as épocas são relativamente curtas (apenas 80 observações), o ganho em acurácia é pequeno e apresenta variabilidade.
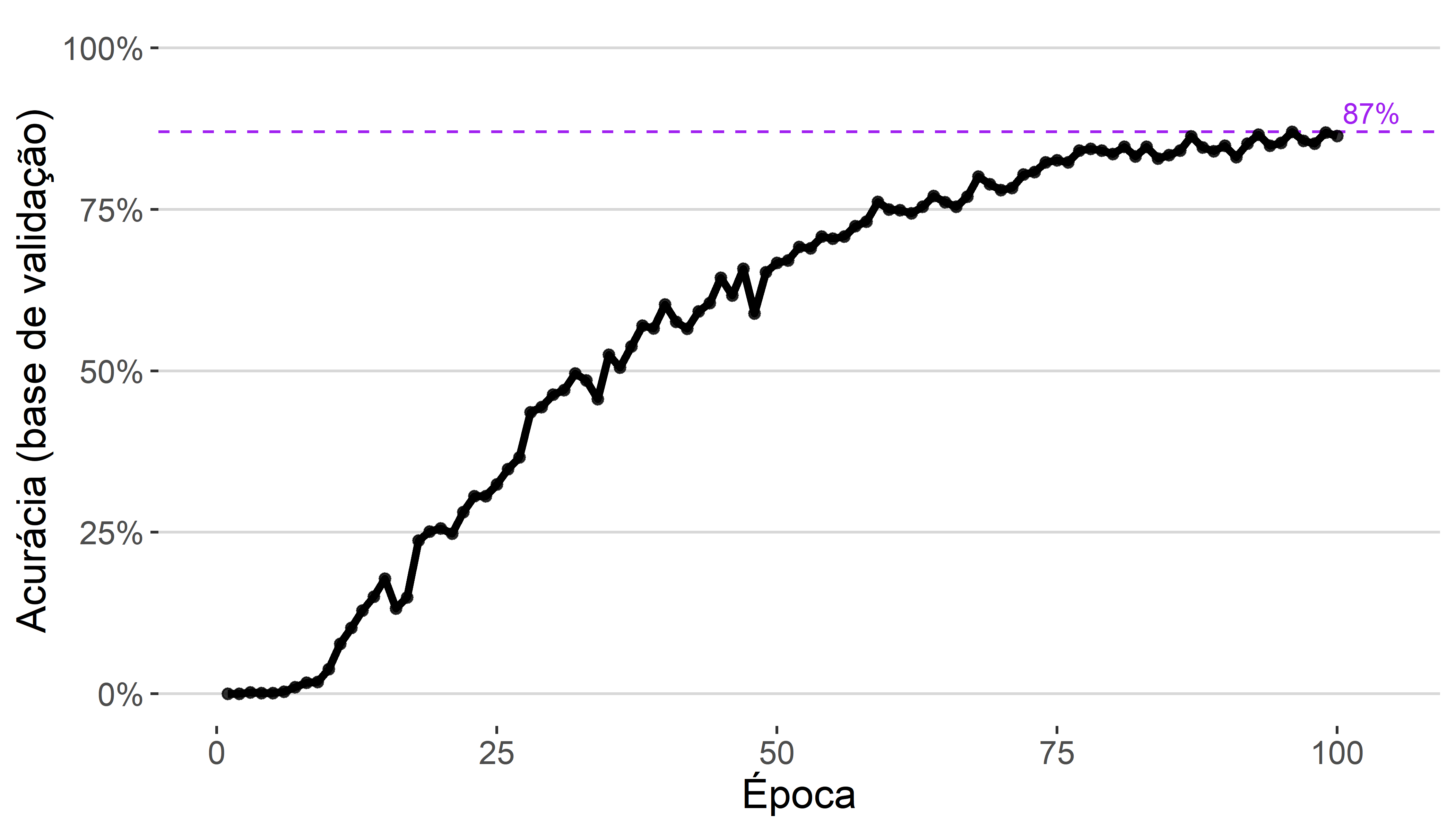
Um possível motivo do Captcha não ter chegado no máximo de acurácia (100% no caso do TJRS) é que a arquitetura e os hiperparâmetros considerados não eram poderosos o suficiente para alcançar o melhor modelo. De qualquer forma, a partir do experimento, conclui-se que a utilização de online learning também é muito promissora. A principal vantagem do método é ser menos burocrático para desenvolvedores, no sentido de que basta passar o modelo inicial e funções para baixar e testar os Captchas para aprimorar o modelo. A desvantagem é que o procedimento precisa de conexão ativa com a internet e o aprendizado é mais lento, já que os dados são baixados no processo de construção dos minibatches.
Pacote captcha
O trabalho de resolução de Captchas pelo autor da tese surgiu no ano de 2016. Como foi comentado na introdução da tese, é muito comum se deparar com desafios de Captchas ao raspar dados do judiciário, já que estes dados não são abertos.
O primeiro Captcha a ser investigado foi o do sistema e-SAJ. O desafio era utilizado no site do TJSP que, depois de alguns anos, passou a utilizar o sistema reCaptcha. O Captcha do e-SAJ faz parte da tese, mas tem como fonte de dados o TJBA, que continua utilizando o desafio até o momento que os sites foram investigados pela última vez, em setembro de 2022.
A primeira abordagem para resolver o Captcha do e-SAJ foi utilizando heurísticas para separar as letras, em 2016. Infelizmente o pacote original, chamado {captchasaj}, foi removido da internet, mas um código legado construído para o TJRS está disponível neste link. Nessa abordagem, as letras primeiro são segmentadas, alimentando um modelo de florestas aleatórias que considera os pixels da imagem como variáveis preditoras e a letra como resposta. Esses trabalhos tiveram contribuições importantes de Fernando Corrêa e Athos Damiani, ambos do IME-USP.
A segunda abordagem para resolver os Captchas foi utilizando o áudio, também em 2016. O código para resolver o Captcha da RFB utilizando áudio está disponível neste link. A ideia de resolução era parecida, passando pelo procedimento de segmentação e depois de modelagem, mas tinha um passo intermediário de processamento envolvendo engenharia de features (KUHN; JOHNSON, 2019). O trabalho teve contribuições importantes de Athos Damiani.
Com o advento da ferramenta TensorFlow para o R (ALLAIRE; TANG, 2022), os modelos para resolver Captchas passaram a utilizar modelos de redes neurais. No início, por falta de conhecimento da área, a arquitetura das redes era demasiadamente complexa. Depois que os primeiros modelos começaram a funcionar, notou-se que as etapas de pré-processamento com segmentação e algumas camadas das redes eram desnecessárias para ajustar os modelos. Essa parte teve grande contribuição de Daniel Falbel, também do IME-USP, que foi a pessoa que introduziu o TensorFlow e a área de deep learning para a comunidade brasileira de R.
Depois de resolver com sucesso alguns Captchas, notou-se que seria possível criar um ambiente completo de modelagem de Captchas. Isso deu origem ao pacote {decryptr} (TRECENTI et al., 2022), que foi construído em 2017. O trabalho teve grandes contribuições de Caio Lente, do curso de Ciência da Computação do IME-USP e outros colegas de faculdade.
Com o passar do tempo, o pacote {decryptr} ficou cada vez mais estável, funcionando como dependência de várias ferramentas utilizadas em trabalhos de jurimetria. O pacote também ganhou um site: https://decryptr.xyz e uma API com acesso gratuito, precisando apenas de uma chave de acesso. A ferramenta ficou bastante popular, com 178 estrelas no GitHub no mês de dezembro de 2022. Essas ferramentas envolveram contribuições principalmente de Caio Lente e Daniel Falbel.
A construção do pacote {captcha} separada do {decryptr} se deu por dois motivos. Primeiro, o pacote {decryptr}, por ser o primeiro a tratar do assunto, possui muitos códigos legados e dificuldades de instalação por conta da dependência do python, necessário para o funcionamento do TensorFlow, que é chamado através do pacote {reticulate} (USHEY; ALLAIRE; TANG, 2022). Além disso, a implementação das técnicas do oráculo envolviam modificações na função de perda, que são mais difíceis de implementar no ambiente do {tensorflow}, justamente por conta da necessidade de conhecer o código python que roda por trás dos códigos em R.
Com o advento do pacote {torch} (FALBEL; LURASCHI, 2022), no entanto, tudo foi facilitado. O pacote não possui dependências com o python, além de ser bastante transparente e flexível na construção da arquitetura do modelo, funções de perda e otimização. O pacote, também construído por Daniel Falbel, é um grande avanço científico e facilitou muito a construção dos códigos desta tese.
O pacote {captcha}, apesar de ter sido construído do zero, foi desenvolvido durante lives realizadas na plataforma Twitch. A construção em lives foi interessante porque era possível obter feedback e ideias da comunidade durante a construção da ferramenta, o que acelerou o desenvolvimento e auxiliou na arquitetura do pacote.
O pacote {captcha} foi construído para funcionar como uma caixa de ferramentas para quem deseja trabalhar com Captchas. O pacote possui funções de leitura, visualização, anotação, preparação de dados, modelagem, carregamento de modelos pré-treinados e predição. O pacote também permite a construção de um fluxo de trabalho para resolver um novo Captcha, criando um novo repositório para orquestrar o passo-a-passo.
Uso básico
A utilização básica do {captcha} envolve as funções read_captcha(), plot(), captcha_annotate(), captcha_load_model() e decrypt(). As funções são explicadas abaixo.
A função read_captcha() lê um vetor de arquivos de imagens e armazena na memória do computador. Por trás, a função utiliza o pacote {magick} para lidar com os tipos de arquivos mais comuns (JPEG, PNG, entre outros).
Código
library(captcha)
exemplo <- "assets/img/dados_tjmg.jpeg"
captcha <- read_captcha(exemplo)
captcha
#> # A tibble: 1 × 7
#> format width height colorspace matte filesize density
#> <chr> <int> <int> <chr> <lgl> <int> <chr>
#> 1 JPEG 100 50 sRGB FALSE 4530 72x72
A função retorna um objeto com a classe captcha, que pode ser utilizada por outros métodos do pacote.
Código
class(captcha)
#> [1] "captcha"O objeto de classe captcha é uma lista com três elementos: $img, que contém imagem lida com o pacote {magick}, $lab, que contém o rótulo da imagem (por padrão, NULL) e $path, que contém o caminho da imagem que foi lida.
Código
str(captcha)
#> Class 'captcha' hidden list of 3
#> $ img :Class 'magick-image' <externalptr>
#> $ lab : NULL
#> $ path: chr "assets/img/dados_tjmg.jpeg"A função read_captcha() possui um parâmetro lab_in_path=, que indica se o rótulo está contido no caminho da imagem. Se lab_in_path=TRUE, a função tentará extrair o rótulo do arquivo, obtendo o texto que vem depois do último _ do caminho, armazenando o resultado no elemento $lab.
Código
exemplo <- "assets/img/mnist128c49c36e13_6297.png"
captcha <- read_captcha(exemplo, lab_in_path = TRUE)
str(captcha)
#> Class 'captcha' hidden list of 3
#> $ img :Class 'magick-image' <externalptr>
#> $ lab : chr "6297"
#> $ path: chr "assets/img/mnist128c49c36e13_6297.png"A função plot() é um método de classe S3 do R básico. A função foi implementada para facilitar a visualização de Captchas. A função recebe uma lista de imagens obtida pela função read_captcha() e mostra o Captcha visualmente, como na Figura 3.10.
Código
exemplo <- "assets/img/dados_tjmg.jpeg"
captcha <- read_captcha(exemplo)
plot(captcha)
captchaUm aspecto interessante da função plot() é que ela lida com uma lista de Captchas. Isso é útil quando o interesse é visualizar vários Captchas de uma vez na imagem. A Figura 3.11 mostra um exemplo de aplicação.
Código
exemplos <- paste0("assets/img/", c(
"dados_tjmg.jpeg",
"dados_esaj.png",
"dados_rfb.png",
"dados_sei.png"
))
captchas <- read_captcha(exemplos)
plot(captchas)
captcha com várias imagensPor padrão, a função plot dispõe as imagens em quatro colunas. Para mudar o padrão, é possível modificar as opções usando options(captcha.print.cols = N), onde N é o número de colunas desejado. A Figura 3.12 mostra um exemplo com duas colunas.
Código
options(captcha.print.cols = 2)
plot(captchas)
captcha com várias imagens, disponibilizadas em duas colunasQuando o vetor de Captchas é muito grande, a função plot() mostra um número máximo de 100 imagens, acompanhado de uma mensagem. O padrão de 100 imagens está organizado em uma grade com 25 linhas e 4 colunas, podendo ser sobrescrito ao combinar as opções captcha.print.cols= e captcha.print.rows=. A Figura 3.13 mostra um exemplo do comportamento da função quando o número de imagens excede 100.
Código
# mais de 100 imagens:
exemplos <- rep("assets/img/dados_tjmg.jpeg", 110)
captchas <- read_captcha(exemplos)
plot(captchas)
#> ℹ Too many images, printing first 100. To override, run
#> • options('captcha.print.rows' = MAX_ROWS)
#> • options('captcha.print.cols' = COLUMNS)
plot() com muitas imagensÉ possível criar subconjuntos de um objeto de classe captcha utilizando o operador [. A função length() também pode ser utilizada para medir a quantidade de imagens lidas. A Figura 3.14 mostra um exemplo dessas operações.
Código
captchas_subset <- captchas[1:20]
length(captchas_subset) # 20
#> [1] 20
plot(captchas_subset)
captchaSe a imagem possui um rótulo, por padrão, a função plot() mostra o rótulo no canto da imagem. A Figura 3.15 mostra um exemplo.
Código
exemplo <- "assets/img/mnist128c49c36e13_6297.png"
captcha <- read_captcha(exemplo, lab_in_path = TRUE)
plot(captcha)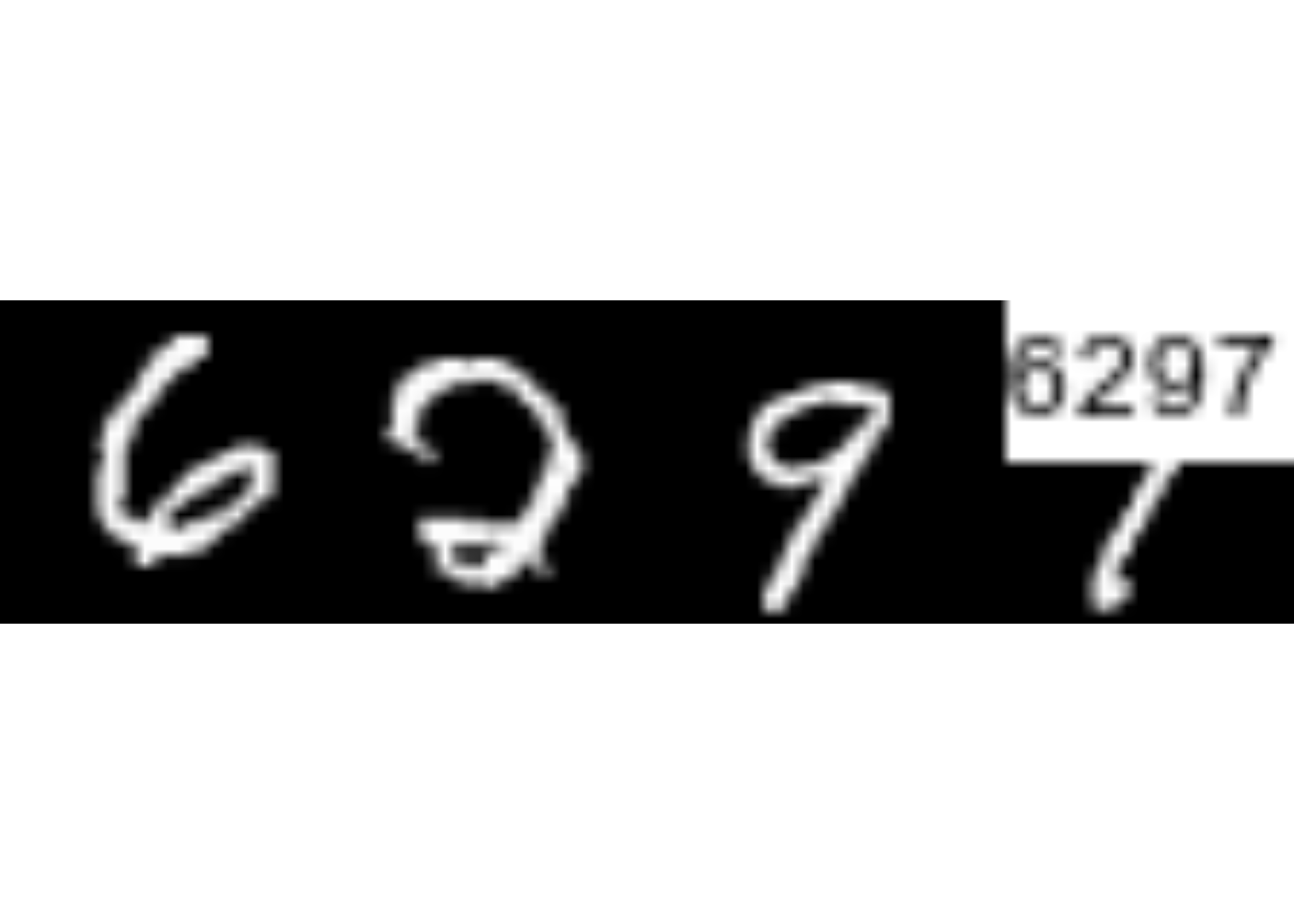
plot() quando o Captcha possui um rótuloA função captcha_annotate() serve para anotar o rótulo de uma imagem de Captcha, manual ou automaticamente. Isso é feito modificando o caminho da imagem, adicionando o texto _rotulo ao final do caminho do arquivo. A função possui os parâmetros listados abaixo:
files=: objeto de classecaptchalido com a funçãoread_captcha()(recomendado) ou vetor de caminhos de arquivos.labels=: (opcional) vetor com os rótulos das imagens. Deve ter o mesmolength()do quefiles=. Por padrão, o valor éNULL, indicando que deve ser aberto umpromptpara que o usuário insira a resposta manualmente.path=: (opcional) caminho da pasta onde os arquivos anotados serão salvos. Por padrão, salva os arquivos com nomes modificados na mesma pasta dos arquivos originais.rm_old=: (opcional) deletar ou não os arquivos originais. Por padrão, éFALSE.
A função, depois de aplicada, retorna um vetor com os caminhos dos arquivos modificados. O parâmetro labels= é útil para lidar com situações em que sabemos o rótulo do Captcha. Por exemplo, em um fluxo de trabalho que utiliza o oráculo, pode ser que um modelo inicial já forneça o valor correto do rótulo.
Quando não existe um rótulo, a função captcha_annotate(), que abre o prompt para anotação e aplica plot() para visualizar a imagem. A Figura 3.16 mostra um exemplo de aplicação da função captcha_annotate() no software RStudio.
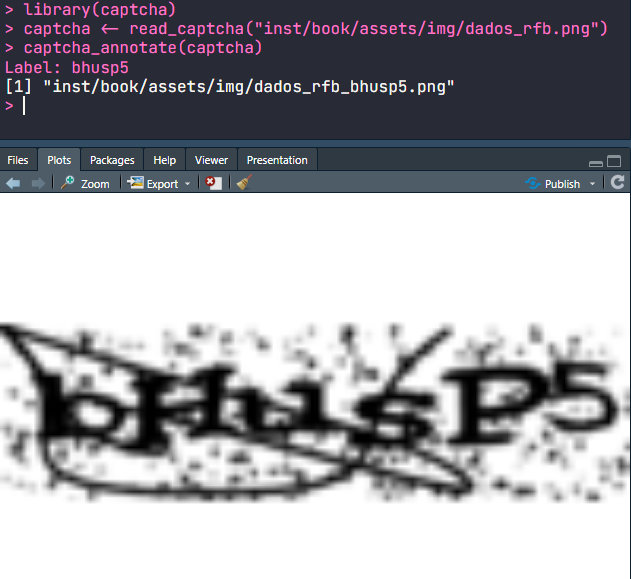
captcha_annotate(). O rótulo bhusp5 foi inserido manualmentePor último, a função decrypt() tem o papel de obter o rótulo de uma imagem utilizando um modelo já treinado para aquele tipo de imagem. A função recebe dois argumentos: file= que pode ser tanto o caminho do arquivo quanto um objeto de classe captcha, e um argumento model=, que contém um modelo de classe luz_module_fitted, ajustado utilizando as ferramentas que serão apresentadas na próxima subseção.
Para a tese, foram desenvolvidos modelos para vários Captchas diferentes. É possível carregar um modelo já treinado usando a função captcha_load_model(), podendo receber em seu único parâmetro path= o caminho de um arquivo contendo um modelo ajustado ou uma string com o nome de um modelo já treinado, como "rfb", por exemplo. Os modelos treinados são armazenados nos releases do repositório do pacote captcha, são baixados e controlados pelo pacote {piggyback} (BOETTIGER; HO, 2022) e são lidos utilizando o pacote {luz}, que será descrito em maiores detalhes na próxima subseção. No momento de submissão da tese, os Captchas com modelos desenvolvidos eram trf5, tjmg, trt, esaj, jucesp, tjpe, tjrs, cadesp, sei e rfb. Mais modelos serão adicionados no futuro.
A Figura 3.17 resume visualmente as funções apresentadas até o momento. As setas indicam a dependência das funções de objetos gerados por outras funções.

{captcha}Modelagem
O pacote {captcha} também fornece uma interface básica para o desenvolvimento de modelos a partir de uma base completamente anotada. A anotação pode ser feita manualmente pela função captcha_annotate(), apresentada anteriormente, ou por outro método desenvolvido pelo usuário.
A parte de modelagem parte de algumas premissas sobre a base de dados. As imagens precisam estar em uma pasta e ter o padrão caminho/do/arquivo/<id>_<lab>.<ext>, onde:
<id>: pode ser qualquer nome, de preferência sem acentuação ou outros caracteres especiais, para evitar problemas de encoding. Geralmente, é um hash identificando o tipo e id do captcha. Nota: ao anotar um caso, é importante que oidseja único, já que dois Captchas podem ter o mesmo rótulo.<lab>: é o rótulo do Captcha. Pode ser um conjunto de caracteres entre[a-zA-Z0-9], diferenciando maiúsculas e minúsculas se necessário. No momento, todos os arquivos em uma pasta devem ter a mesma quantidade de caracteres (comprimento homogêneo). Futuramente, o pacote poderá considerar Captchas de comprimento heterogêneo.<ext>: extensão do arquivo. Pode ser.png,.jpegou.jpg. As operações também funcionam para o formato.svg, mas pode apresentar problemas por conta da transparência da imagem.
Atendidas as premissas da base anotada, é possível ajustar um modelo de redes neurais usando o pacote {captcha}. No entanto, como o ajuste de modelos de redes neurais tem uma série de nuances e pequenas adaptações, optou-se por exportar funções em dois níveis de aprofundamento. A primeira é a automatizada, utilizando a função captcha_fit_model() descrita a seguir, enquanto a segunda é a procedimental, utilizando o passo a passo descrito na Subseção 3.2.3.
A função captcha_fit_model() ajusta um modelo a partir de uma pasta com arquivos anotados. A função recebe os parâmetros: dir=, contendo o caminho dos arquivos anotados; dir_valid=, (opcional) contendo o caminho dos arquivos anotados para validação; prop_valid=, contendo a proporção da base de treino a ser considerada como validação, ignorada quando dir_valid= é fornecida (por padrão, considera-se 20% da base para validação).
A função captcha_fit_model() também possui alguns parâmetros relacionados à modelagem. São eles: dropout=, especificando o percentual de dropout aplicado às camadas ocultas da rede (por padrão, 0.25); dense_units=, especificando a quantidade de unidades na camada oculta que vem depois das camadas convolucionais (por padrão, 200); decay=, especificando o percentual de decaimento da taxa de aprendizado (por padrão, 0.99); epochs= número de épocas (voltas completas na base de treino) para ajuste do modelo (por padrão 100). O modelo está configurado para parar o ajuste após 20 iterações sem redução significativa na função de perda (arbitrado em 1%; para mais detalhes ver a Subseção 3.2.3).
No final, a função retorna um modelo ajustado com classe luz_module_fitted, que pode ser salvo em disco utilizando-se a função luz_save(). O modelo também pode ser serializado para utilização em outros pacotes como pytorch. Um tutorial sobre serialização pode ser encontrado na documentação do pacote torch.
O pacote {captchaOracle} possui uma interface similar para trabalhar com bases com rótulos parciais. Como a estrutura de dados nesse caso é mais complexa e pode evoluir no futuro, os códigos foram organizados em outro pacote. Mais detalhes na Seção A.2.
Na documentação do pacote {captcha}, foi adicionado um exemplo de aplicação. O exemplo utiliza captchas gerados usando a função captcha_generate(), que gera Captchas utilizando o pacote {magick}. O Captcha foi criado para a construção da tese, apelidado de R-Captcha, e possui os seguintes parâmetros:
write_disk=: salvar os arquivos em disco? Por padrão, é falso.path=: Caminho para salvar arquivos em disco, caso o parâmetro anterior seja verdadeiro.chars=: Quais caracteres usar na imagem.n_chars=: O comprimento do Captcha.n_rows=: Altura da imagem, em pixels.n_cols=: Largura da imagem, em pixels.p_rotate=: Probabilidade de rotação da imagem.p_line=: Probabilidade de adicionar um risco entre as letras.p_stroke=: Probabilidade de adicionar uma borda nas letras.p_box=: Probabilidade de adicionar uma caixa (retângulo) em torno das letras.p_implode=: Probabilidade de adicionar efeitos de implosão.p_oilpaint=: Probabilidade de adicionar efeitos de tinta a óleo.p_noise=: Probabilidade de adicionar um ruído branco no fundo da imagem.p_lat=: Probabilidade de aplicar o algoritmo local adaptive thresholding à imagem.
Resolvendo um novo Captcha do zero
Em algumas situações, pode ser desejável rodar modelos de forma customizada. Isso acontece pois modelos de aprendizagem profunda costumam precisar de diversos pequenos ajustes, como na taxa de aprendizado, funções de otimização, camadas computacionais e funções de pré-processamento.
A função captcha_fit_model(), apresentada na subseção anterior, é engessada. Ela aceita alguns parâmetros para estruturar o modelo, mas não possui elementos suficientes para customização. É para isso que pacotes como {torch} e {luz} existem, pois criam ambientes de computação mais flexíveis para operar os modelos de aprendizado profundo.
Outra desvantagem da utilização do captcha_fit_model() é possibilidade de disponibilizar modelos. Um modelo pode ser utilizado localmente, mas a tarefa de disponibilizar as bases de dados e o modelo publicamente não tem um procedimento bem definido.
Para organizar o fluxo de trabalho, implementou-se passo-a-passo de anotação e modelagem de Captchas dentro do pacote {captcha}. A função que orquestra as atividades é a new_captcha(). A função possui apenas um parâmetro, path=, que é o caminho de uma nova pasta a ser criada.
A função também pode ser chamada criando-se um projeto dentro do próprio RStudio. A Figura 3.18 mostra um exemplo de utilização do template dentro do RStudio, após clicar em Novo Projeto > Novo Diretório.
Ao criar um novo projeto, pelo comando new_captcha() ou pela interface do RStudio, uma nova janela é aberta. O projeto contém quatro arquivos:
01_download.R: Contém códigos que auxiliam no desenvolvimento de funções para baixar Captchas de um site. Na prática, as funções que baixam Captchas precisam ser adaptadas porque os sites são organizados de formas muito diferentes.02_annotate.R: Contém um template para anotação manual de Captchas. A anotação manual pode tanto ser realizada usando a interface criada pelo pacote{captcha}quanto externamente. No final, os arquivos anotados devem ser salvos na pastaimg, no formato descrito na Subseção 3.2.2.03_model.R: Contém um template para modelagem, permitindo a customização completa do procedimento de ajuste. O script contém comandos para carregar os dados, especificar o modelo, realizar o ajuste e salvar o modelo ajustado.04_share.R: Contém funções para criar um repositório git da solução e disponibilizar o modelo ajustado. O modelo poderá ser lido e aplicado utilizando-se a funçãocaptcha_load_model(), que pode ser aplicado em diferentes contextos, sem a necessidade de copiar arquivos localmente.
Sobre a parte de modelagem, cabe uma descrição mais detalhada com apresentação de parte do código. O primeiro passo do script é criar objetos do tipo dataset (objeto que armazena os dados de forma consistente) e dataloader (objeto que obtém amostras do dataset, que são utilizadas como os minibatches do modelo), com uma estrutura orquestrada pelo pacote {torch}.
A função captcha_dataset() cria o dataset, recebendo como parâmetro uma pasta de arquivos e gera um objeto com classes my_captcha, dataset e R6. A função é, na verdade, um objeto do tipo dataset_generator, criada utilizando a função dataset() do pacote {torch}. O objeto é chamado da mesma forma que uma função usual do R, aceitando alguns parâmetros adicionais:
transform_image=: operação de transformação a ser aplicada à imagem. Por padrão, utiliza a funçãocaptcha_transform_image(), que lê a imagem e redimensiona para ficar com dimensões32x192. A dimensão foi escolhida para facilitar a implementação das camadas convolucionais e para lidar com o fato de que usualmente os Captchas são imagens retangulares.transform_label=: operação de transformação para gerar a variável resposta. Por padrão, utiliza a funçãocaptcha_transform_label(), que recebe um vetor de todos os possíveis caracteres do Captcha e aplica a operaçãoone_hot(), obtendo-se a versão matricial da resposta com zeros e uns, como descrito na Seção 2.1.1.augmentation=: operações para aumentação de dados. Por exemplo, pode ser uma função que adiciona um ruído aleatório à imagem original para que, ao gerar uma nova amostra, os dados utilizados sejam sempre diferentes.
A função captcha_dataset() deve ser aplicada duas vezes, uma para criar a base de treino e outra para criar a base de validação. A separação de bases de treino e validação deve ser feita de forma manual, copiando parte dos Captchas anotados para uma nova pasta, com aleatorização. É papel do usuário separar as bases em pastas distintas carregá-as em um dataset.
Código
# datasets
captcha_ds <- captcha::captcha_dataset(
root = parm$path_img,
captcha = NULL,
download = FALSE
)Em seguida, os dataloaders são criados utilizando-se a função dataloader() do pacote {torch}. Nessa parte é definido o tamanho do minibatch, além de outros possíveis parâmetros disponíveis na função do {torch}. Para mais detalhes, o usuário pode acessar a documentação da função neste link. Devem ser criados dataloaders tanto para a base de treino quanto para a base de validação.
Código
# dataloaders (training and validation)
captcha_dl_train <- torch::dataloader(
dataset = torch::dataset_subset(captcha_ds, id_train),
batch_size = parm$batch_size,
shuffle = TRUE
)
captcha_dl_valid <- torch::dataloader(
dataset = torch::dataset_subset(captcha_ds, id_valid),
batch_size = parm$batch_size
)A próxima etapa é a especificação do modelo. No script de modelagem, o modelo é fornecido pelo objeto net_captcha do pacote {captcha}. Assim como no caso do dataset, o net_captcha é um objeto especial do {torch}, com classes CAPTCHA-CNN, nn_module e nn_module_generator. O objeto pode ser utilizado como uma função, gerando um módulo do {torch}, similar a uma função de predição. No entanto, por conta da forma que o objeto é utilizado em passos posteriores pelo pacote {luz}, o objeto a ser considerado é mesmo o nn_module_generator, como colocado no script.
Para customizar o modelo, o usuário deve criar um novo módulo modificando os métodos initialize() e forward(), acessados dentro do objeto net_captcha$public_methods. O primeiro é responsável pela inicialização do modelo, contendo a descrição das operações que são realizadas, como convoluções. O segundo é a função feed forward das redes neurais, que recebe uma imagem e retorna um objeto contendo os escores ou probabilidades, no formato da variável resposta.
Por padrão, o código de inicialização do modelo é o descrito abaixo. Os parâmetros input_dim=, output_ndigits=, output_vocab_size= e vocab= descrevem, respectivamente, as dimensões da imagem, o comprimento da resposta, o comprimento do alfabeto e os elementos do alfabeto. Os parâmetros transform=, dropout= e dense_units= controlam, respectivamente, a função de transformação da imagem, os hiperparâmetros de dropout e a quantidade de unidades na camada densa. É possível notar que os parâmetros das convoluções são fixos, já preparados para funcionar bem com uma imagem de dimensões 32x192.
Código
initialize = function(input_dim,
output_ndigits,
output_vocab_size,
vocab,
transform,
dropout = c(.25, .25),
dense_units = 400) {
# in_channels, out_channels, kernel_size, stride = 1, padding = 0
self$batchnorm0 <- torch::nn_batch_norm2d(3)
self$conv1 <- torch::nn_conv2d(3, 32, 3)
self$batchnorm1 <- torch::nn_batch_norm2d(32)
self$conv2 <- torch::nn_conv2d(32, 64, 3)
self$batchnorm2 <- torch::nn_batch_norm2d(64)
self$conv3 <- torch::nn_conv2d(64, 64, 3)
self$batchnorm3 <- torch::nn_batch_norm2d(64)
self$dropout1 <- torch::nn_dropout2d(dropout[1])
self$dropout2 <- torch::nn_dropout2d(dropout[2])
self$fc1 <- torch::nn_linear(
# must be the same as last convnet
in_features = prod(calc_dim_conv(input_dim)) * 64,
out_features = dense_units
)
self$batchnorm_dense <- torch::nn_batch_norm1d(dense_units)
self$fc2 <- torch::nn_linear(
in_features = dense_units,
out_features = output_vocab_size * output_ndigits
)
self$output_vocab_size <- output_vocab_size
self$input_dim <- input_dim
self$output_ndigits <- output_ndigits
self$vocab <- vocab
self$transform <- transform
}A função de feed forward foi descrita abaixo. A função aplica o passo-a-passo descrito na Seção 2.1.2.1, recebendo uma imagem x como entrada e retornando uma matriz com números reais, que dão os pesos (positivos ou negativos) do modelo para cada letra da resposta. O modelo retorna os valores de forma irrestrita, e não os números no intervalo \([0,1]\) porque, no passo seguinte, a função de perda considera como entrada esses valores. Se o usuário decidir modificar o método forward para retornar probabilidades, precisará também adaptar a função de perda utilizada.
Código
forward = function(x) {
out <- x |>
# normalize
self$batchnorm0() |>
# layer 1
self$conv1() |>
torch::nnf_relu() |>
torch::nnf_max_pool2d(2) |>
self$batchnorm1() |>
# layer 2
self$conv2() |>
torch::nnf_relu() |>
torch::nnf_max_pool2d(2) |>
self$batchnorm2() |>
# layer 3
self$conv3() |>
torch::nnf_relu() |>
torch::nnf_max_pool2d(2) |>
self$batchnorm3() |>
# dense
torch::torch_flatten(start_dim = 2) |>
self$dropout1() |>
self$fc1() |>
torch::nnf_relu() |>
self$batchnorm_dense() |>
self$dropout2() |>
self$fc2()
out$view(c(
dim(out)[1],
self$output_ndigits,
self$output_vocab_size
))
}Definida a arquitetura do modelo, o penúltimo passo é o ajuste. O ajuste do modelo é conduzido pelo pacote {luz}, que facilita a criação do loop de ajuste dos parâmetros, desempenhando um papel similar ao que o keras realiza para o tensorflow puro.
No caso dos Captchas, o código {luz} para ajuste do modelo segue quatro passos, encadeados pelo operador pipe, ou |>:
setup(): serve para determinar a função de perda, o otimizador e as métricas a serem acompanhadas. No script, a função de perda utilizada é ann_multilabel_soft_margin_loss()do{torch}, o otimizador é ooptim_adam()do{torch}e a métrica é acaptcha_accuracy(), desenvolvida no pacote{captcha}para apresentar a acurácia considerando a imagem completa do Captcha e não a acurácia de cada letra da imagem, que seria o resultado se fosse utilizada a funçãoluz_metric_accuracy(), do pacote{luz}.set_hparams(): serve para informar os hiperparâmetros e outras informações do modelo. Os parâmetros colocados dentro dessa função são exatamente os parâmetros do métodoinitialize()da rede neural criada no passo anterior.set_opt_hparams(): serve para informar os hiperparâmetros da otimização. Os parâmetros colocados nessa função são passados para a função de otimização. No script, o único parâmetro informado é a taxa de aprendizado, fixada em0.01.fit(): serve para inicializar o loop de ajuste do modelo. Aqui, é necessário passar os dataloaders de treino e validação, a quantidade de épocas (fixada em 100), e os callbacks, que são operações a serem aplicadas em diferentes momentos do ajuste (por exemplo, ao final de cada iteração). Por padrão, os callbacks são:- O decaimento da taxa de aprendizado, utilizando uma taxa multiplicativa. A cada iteração, a taxa de aprendizado decai em um fator determinado pela função definida em
lr_lambda, que por padrão é0.99. Ou seja, em cada época, a taxa de aprendizado fica 1% menor. - A parada adiantada, ou early stopping. Por padrão, está configurado para parar o ajuste do modelo se forem passadas 20 épocas sem que o modelo melhore a acurácia em 1% na base de validação. Por exemplo, se em 20 épocas consecutivas o modelo permanecer com acurácia em 53%, o ajuste será encerrado, mesmo que não tenha passado pelas 100 épocas.
- O arquivo de
log. Por padrão, o modelo guarda o histórico de ajuste em um arquivo do tipo comma separated values (CSV), contendo a perda e a acurácia do modelo na base de treino e na base de validação, ao final de cada época. O arquivo delogé importante para acompanhar o ajuste do modelo e verificar sua performance ao longo das épocas, podendo dar insights sobre possíveis ajustes nos hiperparâmetros.
- O decaimento da taxa de aprendizado, utilizando uma taxa multiplicativa. A cada iteração, a taxa de aprendizado decai em um fator determinado pela função definida em
No final do fluxo definido pelo pacote {luz}, é obtido um modelo ajustado. O modelo possui a classe luz_module_fitted e pode ser investigado ao rodar o objeto no console do R. No exemplo do R-Captcha apresentado na subseção anterior, o objeto possui as características abaixo. O objeto contém um relatório conciso e bastante informativo, mostrando o tempo de ajuste, as métricas obtidas no treino e na validação e a arquitetura do modelo.
A `luz_module_fitted`
── Time ────────────────────────────────────────────────
• Total time: 10m 48.1s
• Avg time per training batch: 415ms
• Avg time per validation batch 217ms
── Results ─────────────────────────────────────────────
Metrics observed in the last epoch.
ℹ Training:
loss: 0.0049
captcha acc: 0.996
ℹ Validation:
loss: 0.0356
captcha acc: 0.905
── Model ───────────────────────────────────────────────
An `nn_module` containing 628,486 parameters.
── Modules ─────────────────────────────────────────────
• batchnorm0: <nn_batch_norm2d> #6 parameters
• conv1: <nn_conv2d> #896 parameters
• batchnorm1: <nn_batch_norm2d> #64 parameters
• conv2: <nn_conv2d> #18,496 parameters
• batchnorm2: <nn_batch_norm2d> #128 parameters
• conv3: <nn_conv2d> #36,928 parameters
• batchnorm3: <nn_batch_norm2d> #128 parameters
• dropout1: <nn_dropout> #0 parameters
• dropout2: <nn_dropout> #0 parameters
• fc1: <nn_linear> #563,400 parameters
• batchnorm_dense: <nn_batch_norm1d> #400 parameters
• fc2: <nn_linear> #8,040 parametersPor último, o modelo deve ser salvo em um arquivo local. Isso é feito utilizando-se a função luz_save() do pacote {luz}, guardando um objeto com extensão .pt, que será disponibilizado no 04_share.R.
Cabe também um detalhamento do script disponibilizado em 04_share.R. O script utiliza o pacote {usethis} (WICKHAM; BRYAN; BARRETT, 2022) para organizar o repositório, configurando o Git (software de versionamento de códigos) e o GitHub (sistema web de organização de repositórios). Além disso, o script utiliza o pacote {piggyback} (BOETTIGER; HO, 2022) para disponibilizar o modelo ajustado nos releases do repositório criado2. Opcionalmente, o usuário poderá também disponibilizar a base com os arquivos anotados em um arquivo .zip, o que é recomendado, pois permite que outras pessoas possam trabalhar com os mesmos dados e aprimorar os modelos.
Uma vez compartilhado nos releases do repositório, o modelo poderá ser lido por qualquer pessoa, em outras máquinas utilizando o pacote {captcha}. Basta rodar o código abaixo e o modelo será carregado.
Código
model <- captcha_load_model("<name>", "<user>/<repo>")Com isso, o trabalho pode ser compartilhado e Captchas podem ser resolvidos de forma colaborativa. O fluxo do new_captcha() é flexível o suficiente para construir modelos customizados e consumidos com o pacote {captcha}.
O fluxo também permite uma adaptação fácil ao método WAWL. Para isso, basta substituir a função de perda e de leitura dos dados pelas funções oferecidas pelo pacote {captchaOracle}, descrito no Apêndice A.
Discussão
Os resultados apresentados nas seções anteriores mostram que o método WAWL possui bons resultados empíricos. Nesta seção, os resultados foram confrontados com as hipóteses de pesquisa definidos na Seção 1.6 de forma crítica.
A primeira hipótese de pesquisa diz respeito à pertinência de utilizar do aprendizado fracamente supervisionado como forma de ajustar modelos para resolver Captchas. A hipótese foi verificada, já que os resultados mostram um incremento significativo na acurácia do modelo em praticamente todas as simulações.
Do ponto de vista teórico, várias pesquisas já apontavam que o aprendizado com rótulos parciais ou rótulos complementares têm boas propriedades. Por isso, já seria esperado que uma nova função de perda, desde que pensada com cuidado, traria resultados positivos.
No entanto, até o momento, não existiam evidências de que a utilização de rótulos parciais ou rótulos complementares teriam bons resultados empíricos em Captchas. Isso foi verificado em todos os 12 Captchas estudados, sendo 10 obtidos do mundo real. Em todos os casos, a função de perda proposta funcionou bem e trouxe ganhos significativos na acurácia do modelo, tanto em termos relativos quanto absolutos. Isso demonstra que a escolha do método se alia bem ao problema que deu origem à pesquisa, que são os Captchas.
Sobre a parte de aplicação iterada do WAWL, o resultado é positivo, mas inconclusivo. A acurácia de 100% encontrada pode sugerir que o método WAWL sempre chegará em um resultado de 100% para qualquer Captcha que surgir. No entanto, pode ser que exista uma limitação na capacidade do modelo, que é habilidade do modelo para se ajustar aos dados a partir dos parâmetros. Pode ser que a arquitetura de rede neural escolhida para resolver o Captcha não seja capaz de chegar a um modelo com 100% de acurácia, independente da quantidade de imagens observadas. É importante olhar o resultado apresentado de forma crítica e compreender que estes podem ser limitados, já que a arquitetura da rede neural não é parte do método WAWL.
A segunda hipótese de pesquisa é a possibilidade de aliar a área de raspagem de dados com a área de modelagem estatística. A hipótese também foi verificada, já que o método WAWL, que utiliza técnicas de raspagem de dados, apresentou bons resultados empíricos.
Neste momento, cabe um comentário sobre o ineditismo da utilização de raspagem de dados em estudos estatísticos. É verdade que existem muitas pesquisas que são possibilitadas por conta dos dados obtidos via raspagem de dados: as pesquisas da ABJ, mencionadas na Seção 1.1 são alguns exemplos. Também existem soluções que utilizam dados provenientes de raspagem de dados para construção de modelos: por exemplo, o DALL-E-2, que é parte de uma base de dados construída utilizando imagens baixadas da internet (MURRAY; MARCHESOTTI; PERRONNIN, 2012; RAMESH et al., 2022). No entanto, até o momento da realização da pesquisa, não foi encontrado nenhum trabalho que utiliza a raspagem de dados como parte do processo de aprendizado estatístico. O método WAWL conecta as áreas de forma intrínseca, podendo ser entendida como uma nova variação de aumentação de dados aplicada a redes neurais convolucionais.
O fato de a raspagem de dados ser relevante para o ajuste de um modelo estatístico pode levar a algumas discussões sobre o ensino da estatística. Primeiro, é importante mencionar que:
- Raspagem de dados não faz parte dos currículos de Bacharelado em Estatística das principais universidades do país3. Logo, pode-se argumentar que raspagem de dados não é uma área de interesse da estatística.
- Raspagem de dados não é uma área de conhecimento bem definida, como álgebra ou análise de sobrevivência. A área é melhor desenvolvida através de aplicações práticas e utilização de ferramentas (como R ou python) do que através de aulas teóricas.
Os resultados levam, então, a um problema de equilíbrio entre pertinência e oportunidade. De um lado, a área de raspagem não se encaixa muito bem no currículo de estatística. Por outro lado, a área expande as possibilidades de atuação de uma profissional da estatística.
Para aliar a pertinência e a oportunidade, uma opção seria oferecer disciplinas optativas de raspagem de dados nos cursos de estatística. Para aumentar a quantidade de potenciais ministrantes, a disciplina poderia ser oferecida em parceria com outros cursos, como ciência da computação, matemática aplicada e engenharias. Dessa forma, as pessoas interessadas teriam a oportunidade de aprender um pouco sobre as técnicas principais, conectando a raspagem de dados com as áreas de conhecimento específicas, como é o caso do Captcha, que alia raspagem de dados com estatística e inteligência artificial. Com isso, conclui-se a discussão sobre a segunda hipótese de pesquisa.
Portanto, as duas hipóteses de pesquisa foram verificadas. No processo de construção do trabalho, no entanto, um terceiro avanço muito importante foi realizado na parte computacional. O pacote {captcha} e os pacotes auxiliares {captchaDownload} e {captchaOracle} são frutos desse trabalho. Pela primeira vez, foi construída uma ferramenta aberta contendo um fluxo de trabalho adaptado para trabalhar com Captchas. Além disso, trata-se de uma das primeiras aplicações completas dos pacotes {torch} e {luz}, que têm potencial de revolucionar a forma em que os modelos estatísticos são desenvolvidos por pessoas que fazem pesquisa em estatística. Os pacotes foram descritos em detalhes no Apêndice A.
Por fim, todos os modelos construídos foram disponibilizados no pacote {captcha}. Os códigos, dados e resultados das simulações estão disponíveis no pacote {captchaOracle}. Os dados utilizados para elaboração da tese estão disponíveis no repositório da tese no GitHub. Dessa forma, a pesquisa pode ser considerada como reprodutível, podendo servir como base para pesquisas futuras.
Para acessar a base, é necessário rodar
remotes::install_github("jtrecenti/doutorado")e depois acessar a base rodandodoutorado::da_results_simulacao.↩︎O script utiliza releases para disponibilizar as soluções porque não é uma boa prática subir arquivos como modelos ajustados ou arquivos brutos de imagens diretamente no repositório. Isso acontece porque o repositório pode ficar demasiadamente pesado e o histórico do Git fica alterado.↩︎
Sites de universidades buscados: USP Butantã (IME), UFSCar, UNESP, Unicamp, USP São Carlos (ICMC), UFBA, UFPR, UFRGS, UFPE, UFAM, UFRN, UFF, ENCE, UFRJ, UFMG, UnB e UFG. A UFSCar possui uma disciplina com conteúdos de raspagem de dados, no entanto, o conteúdo nunca foi desenvolvido com os alunos na prática. Na UFPR, existem cursos de raspagem oferecidos de forma extracurricular.↩︎